
优势与用例
Power BI 提供多种方式,帮助用户开展自助式分析。 例如,组织可以选择采用 托管式自助 BI 模型(而不是集中式的 企业 BI 模型)。 在这种模式下,卓越中心(COE) 或由数据专业人员组成的中央团队负责创建并管理 Power BI 的 Dataset。 业务用户可通过 Power BI Desktop、Excel 或 Fabric 中的其他分析工作负载(例如 notebooks,顺便一提,它们非常棒)来使用这些 Dataset,并使用数据解决业务问题。
托管式自助 BI 模式有多项优势,例如减少对中央 BI 团队的请求,并在可复用的共享 Dataset 中维持单一事实来源。 不过,这种模式也需要在治理方面投入更多精力。 例如,中央团队应培训用户提升其 数据素养,并 监控创建了哪些内容,以及这些内容是怎么被使用的。 另一个针对这些中央 Dataset 的挑战,是如何纳入新数据。
本文将探讨这一挑战通常如何应对,以及复合模型为何可能是一个很有吸引力的解决方案。
丰富或组合集中管理的 Power BI Dataset
随着业务战略不断适应变化,业务对数据的需求也在持续演进。 业务用户经常会要求在上游数据源中新增数据,以便解决新的业务问题。 对中央团队来说,这往往很难管理:既要赋能用户,又要降低风险。 如何既能保持灵活、及时把所需数据交付给用户,又能确保方案可持续,并避免潜在的治理或合规问题?
下图展示了一个常见场景:业务用户希望在现有、集中管理的 Dataset 中,添加一个预测(该预测仅适用于其业务单元或区域)。

在这种情况下,负责管理该 Dataset 的中央团队有多种方式来响应这一请求。 但对这个团队来说,这些选项都不算理想。 要么耗时太多,要么风险太高。 下图展示了三种切实可行的方案。

在复合模型出现之前,团队不得不在以下做法中选择其一:
- 把预测添加到现有 Dataset: 中央团队可以将预测集成到现有 Dataset 或上游数据源中。 这个选项相对简单,也能保留中央“真相”,但随着时间推移,很容易让中央模型被几十个小众来源撑得臃肿。 在缺乏约束的情况下不断添加额外数据,很容易滑向性能问题,并显著提高模型的维护成本。
- 创建新的 Dataset: 中央团队可以复制原始 Dataset,并在副本中加入预测以及用户所需的那部分数据。 视其技能水平而定,也可以由用户自己来管理这个 Dataset。 这种做法可以在不影响中央模型的前提下赋能用户,但也存在明显风险。 两个 Dataset 很可能会出现不同步的情况,而且创建与维护第二个模型需要投入大量精力。 总体而言,复制数据——甚至只是复制带有 DAX 度量值的业务逻辑——都可能导致不理想的结果。
- 在 Excel 中组合: 中央团队可以建议用户在 Excel 中组合数据,使用“在 Excel 中分析”或实时连接表。 这样可以保留中央 Dataset,但用户被迫在 Excel 中手动合并两个来源,出错风险更高,而且工作量也很大。 因此,这个选项同样不理想。
另一个选项是使用 Power BI 复合模型,该功能自 2023 年四月起已正式发布。 复合模型可以用新数据来扩充现有 Dataset。 这样,你既能保留中心模型中的事实与逻辑,又能让用户添加少量数据,用于回答与自身相关的具体问题。
注意复合模型不支持 Direct Lake Dataset。 你只能使用 Direct Query 和 Import 这两种存储模式来组合 Dataset 表。 复合模型本身是一个到 Analysis Services 的 Direct Query 连接,并与其他数据源(包括另一个 Dataset)组合在一起。 |
Power BI 复合模型的使用场景
使用复合模型时,你选择的是一种更偏向于可定制的托管式自助服务模型。 这是因为这些 Dataset 会由一小部分内容创建者进行定制,他们希望加入自己的数据。 不过,这种定制不会改变现有 Dataset,而只是通过新增数据和业务逻辑来丰富它,从而满足他们的数据需求。
下图展示了复合模型的几种使用场景。
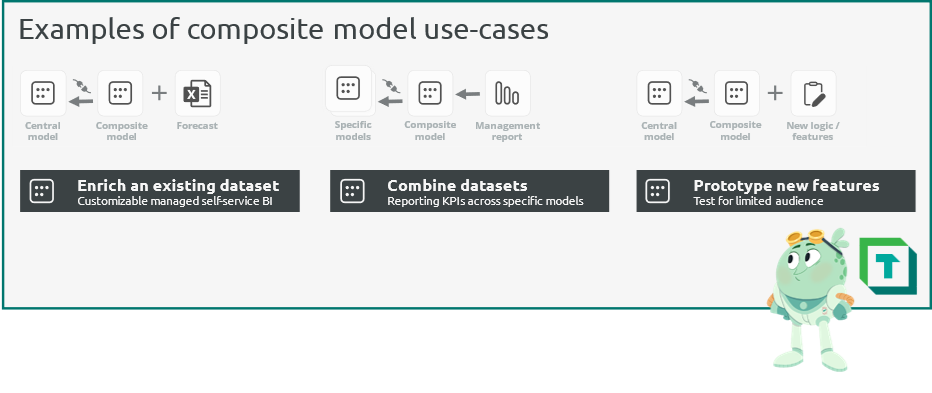
复合模型可用于许多不同场景,例如:
- 丰富现有 Dataset: 复合模型最常见的用法是向集中管理的模型中添加新数据。 在这种场景下,更高级的自助式用户会连接到 Dataset,并从其他来源添加额外数据。 具体示例包括:
- 添加团队特定的目标,例如预算、预测或其他示例。
- 使用不同的主数据。例如,在对销售数据进行销售终端或返利分析时,将客户主数据与你自己的交易数据对齐。
- 添加中心模型未纳入范围的特定数据,例如尚未集成到统一架构中的遗留系统数据。
- 合并数据集:通过复合模型,你可以合并多个数据集。 这有助于创建面向管理层的 Report,例如将特定 Dataset 中的多个 KPI 汇总在一起。
- 原型验证新功能:通过复合模型为现有 Dataset 添加新的业务逻辑,中心团队可以先面向特定目标受众对新功能进行原型设计和测试,再将这些功能纳入中心模型。
更多使用场景信息,已记录在官方的 Microsoft 复合模型指南中。
重要复合模型并不适合作为你 Power BI Dataset 架构的基础。 相反,应将其视为支持特定用例与场景的一个好选择。 例如,复合模型可以在 Personal BI 和 Team BI 使用场景中,让分散的自助式创建者用自己的数据和逻辑来丰富中心模型。 |
充分利用复合模型
复合模型可以带来许多益处。 它们能帮助你保留中心的业务逻辑与数据,同时也让高级用户可以在 Dataset 上实现更多分析。 不过,要成功使用复合模型,需要关注一些关键因素。
- 使用透视:创建复合模型时,自助式创建者可以选择一个 透视。 将透视整理为对使用者有帮助的常用视图,可以带来更便捷的体验。 此外,它还能帮助你更好地利用 Power BI 中的其他功能,例如在 Report 中的 个性化 Visual 功能。 “个性化 Visual”是一种很实用的方式,可为不想因创建新数据和新的 Report 项目而增加麻烦与复杂度的用户,提供自助式分析能力。 你可以使用 Tabular Editor 2 或 Tabular Editor 3,在 Power BI 的 Dataset 中创建和管理透视。
- 挑选并培训用户,以便有效使用:鉴于其影响与限制,复合模型需要在用户赋能方面给予特别关注。 需要认真考虑哪些人会从该功能中受益,以及你打算如何培训他们使用。 这类培训要聚焦使用场景与限制,以及如何识别并处理这些限制。 此外,确保中心团队成员了解在优化复合模型时需要特别注意的事项。 请仔细阅读 Microsoft 的复合模型指南。
- 提供有用、简洁的文档:当连接到复合模型时,用户无法看到对象定义,例如 DAX 公式或分区查询。 对于想加入自定义逻辑的用户来说,这会带来复杂甚至令人沮丧的情况,因为他们缺乏对底层中心模型的足够透明度。 在这种情况下,即使用户能力很强,也会更容易写出错误或性能较差的代码。 为避免出现这种情况,你可以考虑提升模型透明度的方法,例如公开数据字典、文档,甚至把 DAX 表达式写进对象说明中。 实现这些事项的一个实用方法是借助 Tabular Editor C# Script。
- 使用 Dataset 认可:考虑采取必要措施,在组织内提升 数据发现 和 数据民主化。 确保可信的高质量数据源易于查找和识别。 一种简单直接的做法是利用 Fabric 的 认可 和 可发现性 功能,让用户更容易找到 Dataset(例如在 OneLake Data Hub 中)。
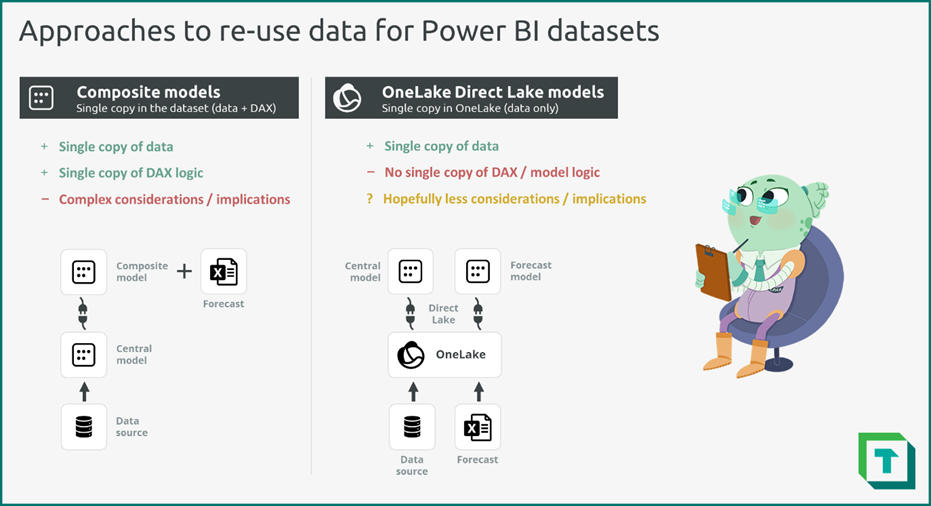
- 避免不必要的 Dataset 链式依赖:在复合模型中,你可能会想把它用于所有用例,但这可能导致业务逻辑或数据的重复。 不过,复合模型会带来多种 性能影响,使得这可能并不是一个理想选择。 和所有设计决策一样,这取决于你的数据、模型,以及场景中的具体业务逻辑。 认真评估你能用的所有替代方案,比如利用 Power BI Dataflows 来复用一致性维度,或者结合 Tabular Editor 与脚本/自动化,使用 Master Model Pattern 来更好地管理可复用的模型逻辑。
- 考虑替代方案:在 Microsoft Fabric 中,除了复合模型之外,还有其他选择。 当你希望在保留单一权威事实来源的同时,允许用户添加自己的数据时,可以考虑利用 OneLake 的“单一副本理念”。 当 Power BI Dataset 使用 Direct Lake 存储模式并连接到同一个数据源时,数据不会被重复复制。 这意味着你可以创建两个使用同一份数据的 Direct Lake Dataset,而无需重复复制这些信息。 不过,DAX 公式中的业务逻辑以及模型关系是在 Dataset 中配置的。 因此,这些逻辑在不同的 Dataset 之间仍会重复,需要仔细管理(例如使用上一条里提到的 Master Model Pattern)。
注意OneLake 是 Microsoft Fabric 的一部分,而 Fabric 目前处于 预览 阶段。 本文讨论的 Fabric 功能会随着时间推移而变化。 |
与任何模型设计决策一样,请仔细评估可用的选项。 在应用这些选项之前,先进行测试,权衡利弊,并评估它们对功能、性能及其他相关因素的影响。
结论
复合模型为一个常见问题提供了优雅的解决方案:既允许最终用户引入新数据,又能保留集中式逻辑和单一事实来源。 尽管需要考虑一些关键因素及其影响,复合模型仍是一个实用的选择,可让高级自助用户在 Power BI 和 Fabric 中发挥更大作用。
注意Tabular Editor 3 即将支持复合模型。 在此期间,或者如果你使用的是 Tabular Editor 2,你可以使用脚本功能在 Tabular Editor 中连接、管理并创建复合模型。 想了解更多,请阅读 Daniel Otykier 的这篇文章。 |
