
Key takeaways
- LLMs can now query semantic models: This article explores how to do it and the factors you should be aware of.
- Design for different user types: Your solution should serve analysts, business users, and everyone in between.
- Quality depends on your model and QA: High-quality DAX needs strong semantic model metadata and robust quality assurance; don't over-trust an LLM that can mask underlying model issues.
This summary is produced by the author, and not by AI.
Large Language Models (LLMs) are a rapidly evolving technology with the potential for revolutionizing how technical and non-technical people interact with Business Intelligence. However, it can be tricky to separate the potential from the hype. In this installment of our exploration of LLMs and Semantic Models, we will explore how to use LLMs to query semantic models and what factors to be aware of to maximize the chance of success. You can read our previous blog post for a high-level overview of LLMs and semantic models.
From questions to DAX
In this post, we first explore how to accommodate the needs of both technical and non-technical users. Then we describe the overall workflow for implementing a reliable LLM-assisted question-to-DAX system describing all the most crucial steps. Afterwards, we discuss the key pillars of success. Finally, we round off with how to get started and the future of this exciting technology. Let’s kick it off!
Different needs for different users
Designing LLM-enabled DAX systems depends on the needs and expertise of the users they serve. Imagine two users: Alice the Analyst and Bob the Business user. While they send each other a lot of letters, they have very different expertise. Alice is fluent in several dialects of SQL and has her computer plastered with BI conference stickers. Bob, on the other hand, just wants to quickly get answers to important business questions and couldn’t care less about the difference between DIVIDE and the division operator.
For Alice the Analyst, what she needs is to accelerate her own exploration of the data. The LLM solution should act as a copilot that can rapidly guide her toward the right solution. The solution needn’t be 100% correct in the first try – Alice has the capabilities to build upon it. Furthermore, the solution needs to provide deep technical comments in the code to help Alice learn – and catch bugs.
Bob the Business user, on the other hand, needs accurate answers to his business questions. While deep in domain knowledge, he lacks the technical expertise to spot flaws in his DAX. Therefore, it's crucial that the solution has robust disambiguation flows to ensure that it reliably answers the question that Bob actually asks. The solution also needs to transparently explain the assumptions within the answer in plain language to help Bob leverage his domain intuition.
While Alice and Bob have different needs, creating effective solutions leverages the same overarching workflow. We describe this in the next section.
Workflow: translating natural language to BI insights
The diagram below describes the high level workflow for translating a user query into working DAX queries. It consists of both steps and feedback loops to ensure assumptions are validated as early as possible. It's inspired by Google’s widely used workflow for turning text into SQL – with important adaptations to DAX.
Below, we describe each step in turn:
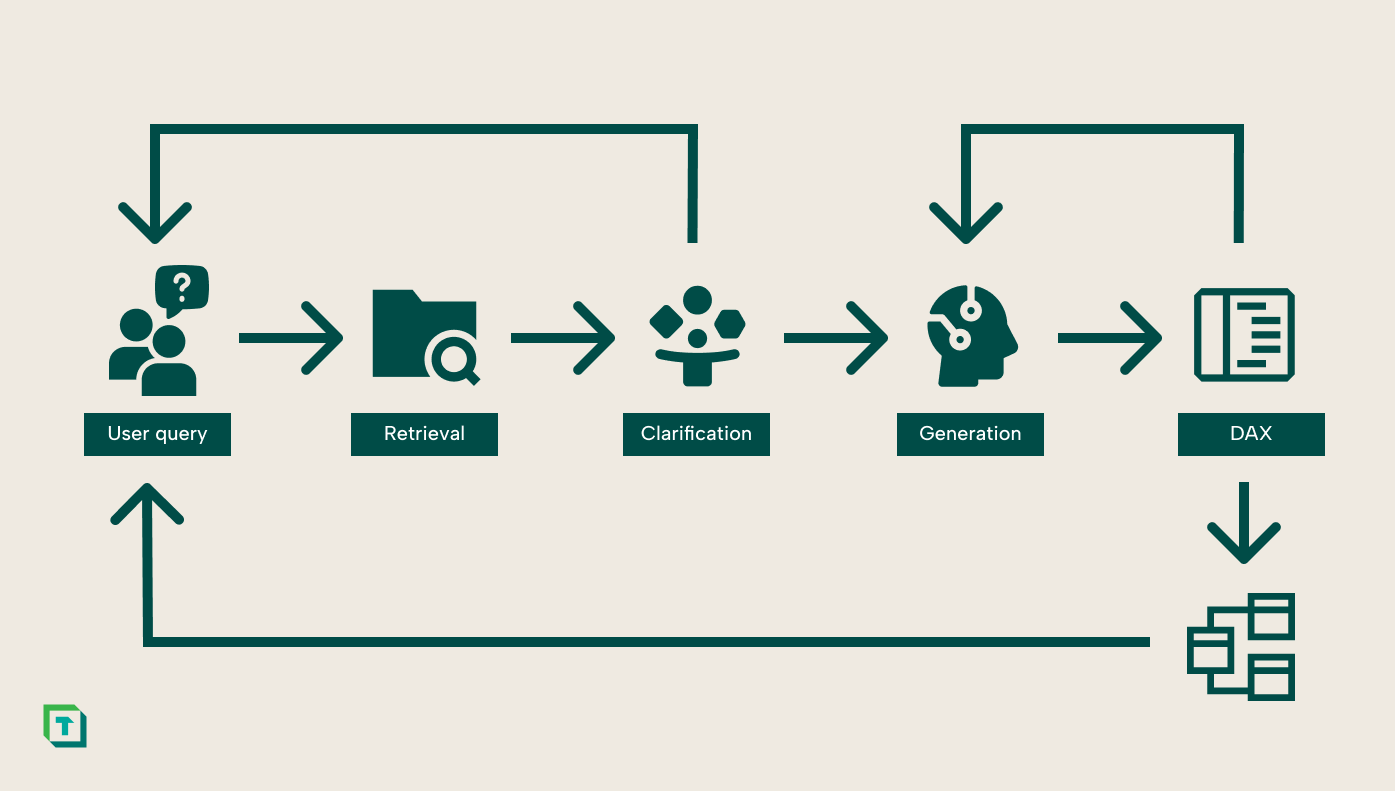
Step 1: user query
Every interaction begins with the user asking a question to the system. While this step seems almost too trivial to mention, it shapes the success of the entire workflow since any natural language query will have a lot of potentially hidden complexity. Ensuring the user and system are aligned on this complexity is extremely important.
Take, for instance, the question “What was our most popular product last year?”. While seemingly straightforward, the question has many ambiguities depending on the specific interpretation of popular, product, and even year.
Step 2: retrieval
After receiving a query, the system conducts a semantic search to identify the most relevant tables and measures from the Semantic Model. In a nutshell, semantic search uses neural text embedding models to identify elements with a similar meaning to the query.
For our "popular product" example, the retrieval system would identify relevant elements such as product tables and dimensions, sales-related measures like Total Revenue and Unit Sales, and time-related dimensions including date tables and fiscal year definitions.
Crafting a strong semantic search system is both a science and an art. However, how much effort to spend on the engineering depends on how strong the LLMs you have access to are. Frontier LLMs like Google’s newest Gemini model can process up to 1 million tokens, which is approximately 1,500 pages of context. For these models, you might be better off by providing more context and let the LLM find the needle in the haystack. If you're instead using smaller, local models (say, for security or privacy models), you can invest more in the retrieval system. In either case, a good starting point is choosing an embedding model that performs well on retrieval on the MTEB leaderboard and fits within your infrastructure constraints.
Step 3: clarification
Once you have the query and relevant context, the next step is to analyze whether the query has a single, unambiguous answer or requires further clarification. In our example, popular could mean the highest number of units sold, the highest revenue generated, the biggest year-over-year growth, the most frequently ordered, the highest profit margin, or the most mentions in customer feedback. Similarly, last year could mean the previous calendar year, last 12 months, last fiscal year, or last complete business period. Crucially, the need for clarification is inversely proportional to the quality of the semantic model. A model rich with definitions will inherently have fewer ambiguities to begin with.
One way to approach this is to get the LLM to generate different answers based on the context and the query. If the LLM finds many different interpretations, there's probably a need for clarification. Then the LLM can identify which questions most effectively narrow down the options and ask those questions to the user, kicking in the first feedback loop.
Step 4 and 5: generation and validation
Once the user's intent is clarified, it's time to generate the DAX query. Here, the ideal path depends on the user. For Bob the Business user, the primary goal is to find and use a preexisting measure that encapsulates the business logic. For Alice the Analyst, the LLM may act more as a copilot, generating novel DAX for new, exploratory measures. In either case, a useful technique is to add a few examples of good DAX queries – what's also called in-context learning. This ensures that the model is up-to-date on stylistic preferences and best practices.
Once the candidate code has been generated, it needs to be validated. Here, static analysis tools like DAX Optimizer and Best Practice Analyzer (available through Tabular Editor) can help provide feedback for the model to improve the queries before running them against live data. If the validation fails, the model can improve the query through the error messages until it passes in the second feedback loop.
Step 6: execution
The final step is to run the validated DAX against the semantic model to return results to the user. Here, it's important that the LLM contextualizes the results. The most trustworthy explanations are those that surface the metadata directly from the semantic model, transparently showing the user the definitions and assumptions (e.g., 'Popularity is being measured by Total Revenue, as defined in the Sales measure...') that the query is built upon.
Ensuring high-quality LLM-generated DAX
While the above workflow is a good scaffold for implementing automated DAX generation, there's a couple of elements needed to ensure success.
Strong semantic models
Semantic models are the brain of the system. The old machine learning maxim, “Garbage In, Garbage Out”, isn't just a warning but a fundamental principle. While the LLM acts as an interpreter, the semantic model is the book it reads from – if the book is poorly written, no amount of interpretation can save it. To make sense of the relationships, the LLM needs meaningful descriptions and synonyms, high referential integrity, and efficient star-shaped relationships. Otherwise, it will inevitably produce hallucinated and inaccurate slop. This semantic model-first view reinforces a crucial argument gaining traction in the field: natural language interaction isn't magic; it's semantic modeling done right. Our workflow is built on this foundational premise.
Poor metadata provides no context: table names like Tbl1 with columns Col_A and measures Calc1 offer no guidance. Rich metadata gives the model useful context: Sales Transactions table containing all completed sales transactions including online and in-store purchases with Transaction_Date described as Date when the sale was completed, used for time-based analysis and synonyms like sale date, purchase date, order date. These additions are the first line of defense against ambiguity. While an LLM can ask for clarification for terms like popular, a well-designed semantic model that already defines key business concepts (like High-margin products and year-over-year growth) preemptively answers these questions. These factors reduce the interpretative burden on the LLM and create a more reliable experience than a standard text-to-SQL approach.
The importance of high-quality metadata applies equally to the underlying data. Having high degrees of missing data, poorly specified data types, or incorrectly formatted values can all lead to poor performance from the LLM. Garbage is garbage – both for data and metadata.
Avoiding LLM-induced brittleness
As previously mentioned, a strong LLM can partially overcome the limitations of a weaker semantic model. However, this overreliance can create a brittle system. Overreliance on LLM reasoning is a form of technical debt that can mask underlying issues in the semantic model. It's always more robust to improve the definitions and measures in the semantic model than to have the LLM navigate its flaws.
Quality assurance
The second pillar is to have robust quality assurance frameworks in place. While static analysis is an important component, it's essential to create custom mini-benchmarks to validate the workflow on your data. A mini benchmark is simply a collection of queries where you know the correct answer in advance, for instance, through running them by trusted human analysts. The benchmarks ensure you have an overview of the reliability of the solution – and know which parts to include. The process of creating mini benchmarks also creates a positive feedback loop. When the system fails a benchmark, it provides an opportunity not only to refine the LLM workflow but also to identify and fix a gap or ambiguity in the semantic model itself.
An equally important part of quality assurance is to test whether your users can correctly interpret the results from the LLMs. These tests can similarly be structured as mini benchmarks, where you take queries that are deliberately ambiguous (e.g., that have multiple interpretations or can't be answered completely by the data) and check that a) the LLMs appropriately caveats these limitations and b) the users understand the LLMs' caveats. A recent paper by my colleagues at Oxford shows that humans often misinterpret LLMs, which causes worse performance than either humans with access to normal search or unassisted LLMs in a medical context.
Bridging LLMs and data with MCP
While we've explored each element in the query-to-DAX workflow, a crucial step remains: How do we provide the data to the LLM? Recently, the field is converging on the Model Context Protocols (MCP) as an open standard (although other protocols exist too, like ACP and A2A, which themselves have their own potential use-cases). MCP was developed by the AI firm Anthropic and they describe it as the “USB-C of AI applications”. It creates a standardized way of interfacing with all kinds of tools; including access to databases and code analyzers.
In the context of the workflow, MCP provides the protocol for both Retrieval and DAX validation. Through this, we can ensure that the LLM receives the results in a familiar way and we can add the necessary security and validation steps as part of the integration.
One example of an MCP server is the Tabular MCP Server, which uses ADOMD to connect to a Tabular model. It gives the LLM access to functions such as GetTableDetails, ListMeasures, and RunQuery. This MCP server could provide a starting point for implementing your own integrations. Note that using a similar approach would only connect to local Power BI Desktop files and can't connect to the XMLA endpoint, which would be a requirement for more scalable systems.
For a more complete overview of BI-relevant MCP servers, check out the recent Tabular Editor blog post by Kurt Buhler.
Getting started and looking to the future
It doesn't require a massive up-front investment to get started with experimenting with LLM-powered BI. You can start with a simple, well-documented semantic model. Then you set up a minimal MCP server (for instance, based on the Tabular MCP Server) with a retrieval function and a DAX validation function. Afterwards, you can use the OpenAI API to set up a simple workflow that implements each of these steps. Finally, you construct 10 high-quality queries with answers that can be used as a mini benchmark to evaluate your system against. And hey presto, you have a solid scaffold for a powerful query to DAX insight system!
Of course, there are more complexities in scaling this workflow to production. Successfully implementing the workflow requires cross-functional collaboration between BI practitioners, AI engineers, and security specialists. The team needs to understand both the important questions to get right and how to rigorously evaluate them.
Still, the future of LLM-assisted BI is bright. LLMs keep on improving their reasoning abilities, the technology stack is maturing and converging (as evidenced by MCP), and more and more valuable use cases are popping up. Still, having the organizational agility to leverage this progress requires focused experiments. And there's no better time to start than today.
For further reading
- Documenting semantic models with LLMs (Tabular Editor). The follow-up in this series, showing how LLM workflows can automate measure documentation and synonym enrichment for the same semantic model metadata that makes querying more reliable.
- How BI tools could change with MCP servers and AI integration (Tabular Editor). Covers the MCP standard introduced in the workflow section, with context on how BI tools expose model metadata and query execution to LLM clients.
- MTEB leaderboard (Hugging Face). Reference point for comparing embedding models when designing the retrieval step in a question-to-DAX workflow.
- Prepare your semantic model for AI (Microsoft Learn). Microsoft's tutorial on adding descriptions, hiding unused fields, and structuring a model so AI, including LLM-generated DAX pipelines, can interpret it reliably.
In conclusion
LLMs make it genuinely possible to query semantic models in natural language, but the results are only as good as the foundation underneath them. Accommodate different user types, invest in high-quality model metadata, and put quality assurance in place so a confident-sounding LLM can't mask underlying problems. With Model Context Protocols emerging to bridge LLMs and data, now is a good time to start experimenting, carefully.
Ground LLM querying in semantic models reviewed with Tabular Editor 3.
Give Tabular Editor a spin

