
Key takeaways
- Working with an LLM is a skill: It takes practice and deliberate planning; good results don't magically appear from better models alone.
- No context means bad DAX: Using AI to write DAX without good context leads to poor results, especially for newer features like DAX functions.
- In-prompt context doesn't persist: You can provide examples in prompts, but it doesn't carry across sessions and is inefficient.
- Let AI fetch its own context: You can ask AI to retrieve context with tools or code, though doing this every session is also inefficient.
- Reusable context scales best: Add instructions, documents, and repositories as project context, composed as well-scoped, reusable markdown files.
- Always apply critical thinking: Even with perfect context, AI can miss edge cases, so challenge and test its output; working code isn't always correct code.
This summary is produced by the author, and not by AI.
Before you get started
If you’re reading this article, then you are likely interested in using AI to help you work with Power BI. Here are a few tips you should know before we start:
- Make sure you are aware of some of the basics about how LLMs work, and some caveats and limitations. This is important so you can apply the appropriate critical thinking and scepticism, skills that are essential to using AI effectively. Make sure that you understand the nuances of LLM mistakes beyond hallucinations, such as how information can be presented out of its original context, which changes its meaning to a reader.
- Set the appropriate expectations. If you start using AI thinking it will make semantic models and reports for you, you are going to waste a lot of time and resources. Instead, focus on how it can augment your workflow in certain areas.
- You should be working with the Power BI Project format for semantic models and reports. You should also consider using the TMDL and PBIR formats. This is essential for AI tools to read and write to your semantic models and reports. The PBIR format, for instance, is mandatory; Microsoft doesn’t support modifying the legacy report metadata formats and will eventually retire them.
The rest of this article focuses on how you can use AI effectively to help you write and work with DAX functions.
Generating correct DAX UDFs with AI
A current challenge for using AI for Power BI development is the recent number of massive changes to the Power BI ecosystem. There have been sweeping changes affecting metadata formats, features, and tools, all of which are sparse or nonexistent in the training data of frontier large language models. Since the abundance and diversity of this information helps determine the success and usefulness of LLMs, this is a problem if we want to use AI to enhance or support Power BI development (or try to automate it entirely, if wasting time and money is your goal).
Ask an LLM to write DAX without context
Consider the following example, where we try to get ChatGPT to generate a DAX function for a moving average:
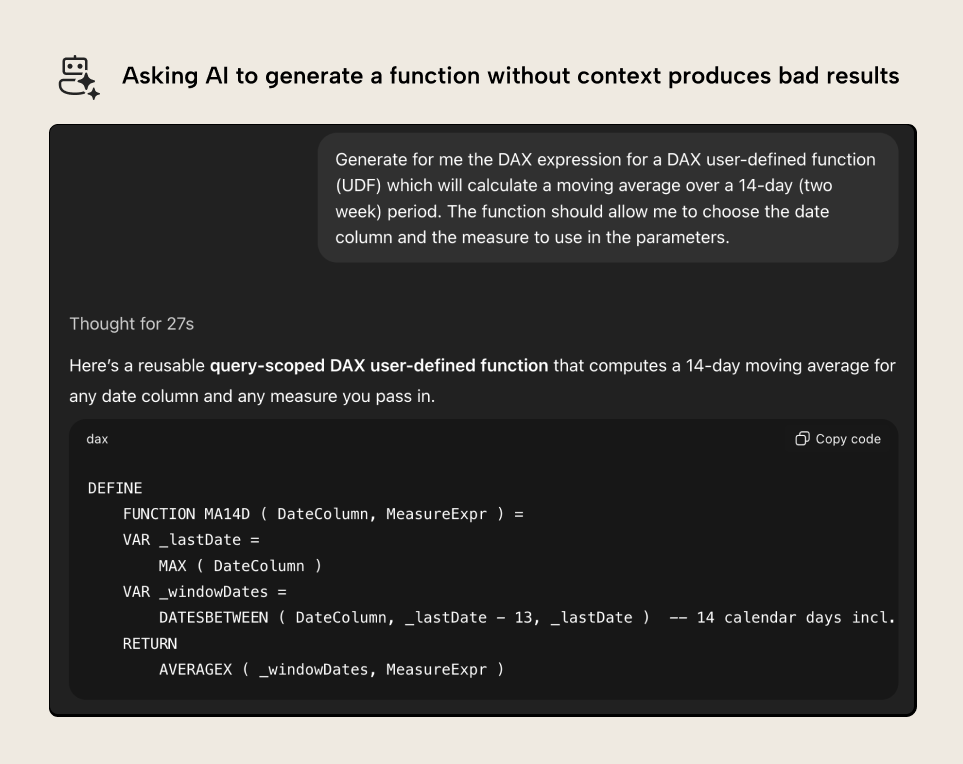
A valiant effort, yet this example produced by ChatGPT is incorrect. It doesn’t use the correct syntax, and the resulting DAX is invalid. This is logical; ChatGPT doesn’t know what a DAX function is. As of writing this article, its training data has a cutoff before DAX functions were widely documented. Even if you are reading this months (or years) into the future, DAX functions will still be very sparse compared to other DAX examples, or semantically similar things in different coding languages.
Providing the context in your prompt
To overcome this limitation, you need to provide sufficient examples for the LLM. You could manually provide a description of the syntax with an example in the prompt. However, this is time consuming and inefficient. Prompts are ephemeral; you will need to do this again in every chat. You can see an example of this in Copilot in the DAX Query view of Power BI, below:
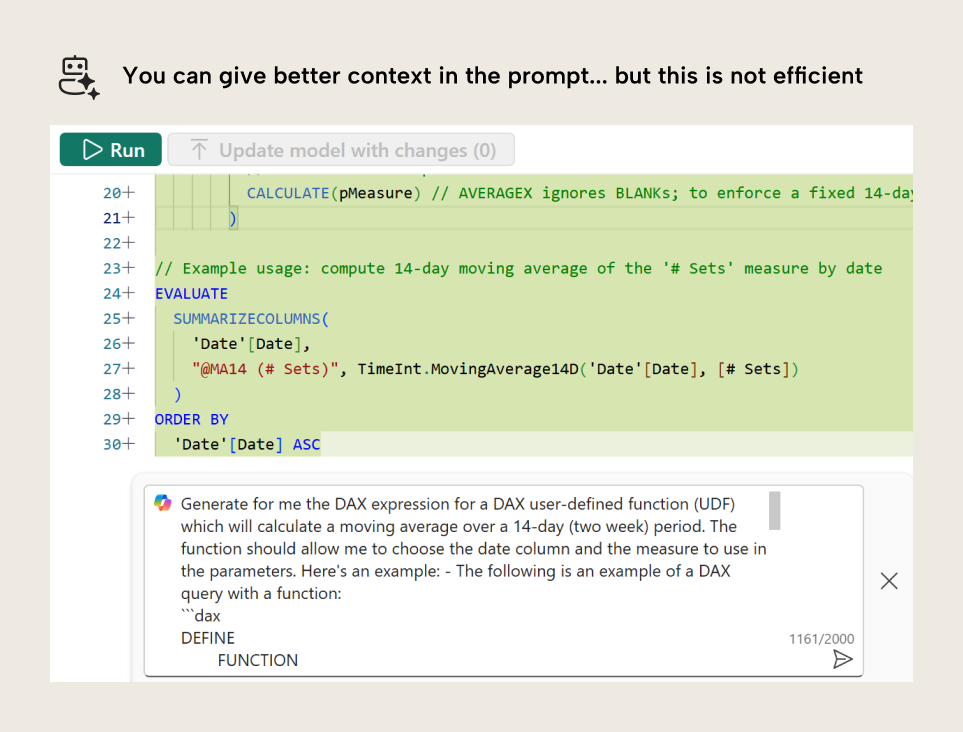
Copilot in Power BI is better than ChatGPT because it can automatically retrieve context from your model and run the DAX through a parser to ensure that your query will execute. However, like Chat, Copilot doesn't (yet) know anything about DAX functions, either. To overcome this, we could provide an example in the prompt; it does work if the prompt is descriptive enough (note we are at 1.2k characters, though). But… to be honest… this way of using AI is wasting your time. You are better off to simply write the code yourself and test it.
In a prompt, it is better to focus on providing the specific instructions for the task, and providing special context only when it is necessary. Other examples of this might be cases like:
- Copying DAX or Power Query code to the prompt.
- Copying your model.bim or .tmdl files to the prompt.
- Copying error messages, screenshots, or other information.
Asking the AI tool to get context itself
Instead, you might ask the LLM to get context and examples itself by using tools that are available. For instance, if it has tools to search and fetch data from the web, you could provide it a link to the Microsoft documentation, or to the DAX Lib GitHub repository. Consider the following example in Claude, which is often considered a better and more convenient tool for generating and working with code:
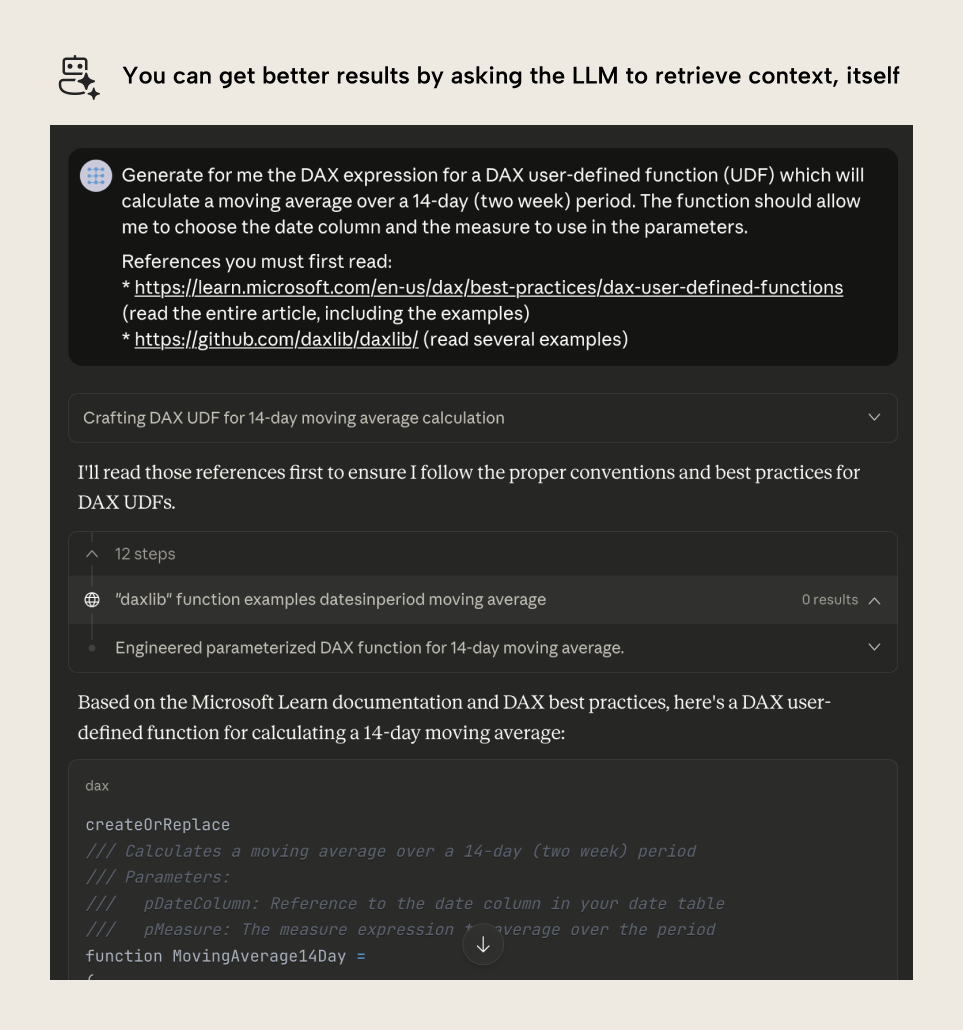
In the example, rather than describing UDFs in the prompt, the user asks Claude to retrieve relevant context from documentation. This costs more tokens and context, but it allows Claude to get better information about what a UDF is and how it works. This is especially valuable since UDFs have some complex and nuanced concepts with type hints.
Note, however, that the result is still not ideal. Because Claude checked TMDL script examples from DAX Lib, it created a TMDL script rather than returning just the DAX expression.
Tools are very useful, particularly WebSearch and WebFetch. However, know that AI cannot differentiate a "good" or “true” source from a bad or AI-generated (or hallucinated) one. When you ask an AI to retrieve context from the web, you should already know ahead of time what the trusted sources are that you want to use. If you don’t know, then that means you should probably spend some time researching yourself, first. Trust me, future you will thank past you for doing that.
Of course, these are just some simple, built-in tools. You can also use MCP servers to let the AI retrieve context in countless other ways, including browsing models and reports, querying models or data sources, and so on.
Setting up re-usable context
However, even using tools, it doesn't make sense to retrieve the same external information for every future chat that you need to use. If you do this, you can quickly end up using your available “token budget”, or just waste time waiting for the LLM to fetch and retrieve sources. Instead, once you identify the context you need, you should isolate it in a re-usable environment.
An example of this is a repository for GitHub Copilot or agentic command-line tools, or a project in Claude:
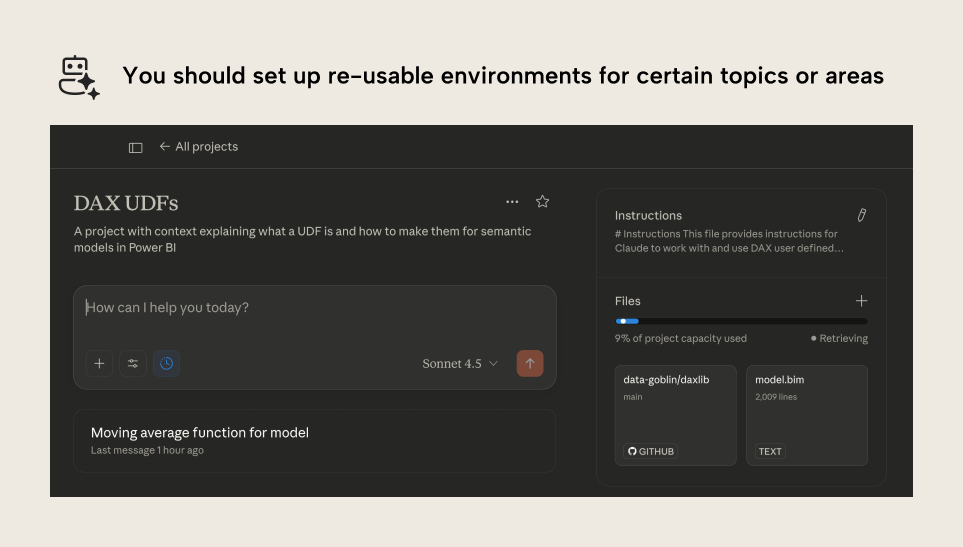
A project allows you to put a set of re-usable instructions, files, and other information in one place to use over multiple sessions with different prompts. It is a specialized environment that you set up for certain tasks (in this case, producing UDFs). Projects are particularly valuable if you use Git integration in Fabric, because you can connect to your remote repository and let Claude search it to view metadata files, like your models, reports, notebooks, and more. Projects also let you define special instructions that are automatically loaded into context for each chat, like the following:
# Instructions
This file provides instructions for Claude to work with and use DAX user defined functions (UDFs), also called DAX functions
# Critical
- Read the project context for information about User Defined Functions (UDFs) in DAX at the start of each session before trying to answer any questions or generate any code.
- When asked for DAX functions, only return the function DAX expression. Do not provide the `FUNCTION` keyword or descriptions with `///`. Generate functions that follow good practices.
Here is one example:
<functionexample>
```dax
// Calculate the maximum for a value plotted on an SVG
(
// The actual you will measure
// Expects a measure reference
pActual : SCALAR EXPR,
// The target you will compare to
// Expects a measure reference
pTarget : SCALAR EXPR,
// The scope of the data for which the SVG will be used
// Expects a table expression
pDataScope : EXPR
)
=>
VAR _Scope = pDataScope
VAR _MaxActualsInScope =
CALCULATE(
MAXX( _Scope, pActual ),
_Scope
)
VAR _MaxTargetInScope =
CALCULATE(
MAXX( _Scope, pTarget ),
_Scope
)
VAR _Result =
MAX( _MaxActualsInScope, _MaxTargetInScope ) * 1.1
RETURN
_Result
```
</functionexample>
## Check the following references when appropriate:
<references>
- Microsoft Docs: Use the Microsoft Docs MCP server
- Microsoft Docs: DAX Functions (UDFs) docs <example>https://learn.microsoft.com/en-us/dax/best-practices/dax-user-defined-functions</example>
- DAXLib.org library for DAX functions https://github.com/daxlib/daxlib/tree/main/packages <example>https://raw.githubusercontent.com/daxlib/daxlib/refs/heads/main/packages/d/daxlib.formatstring/0.1.2/lib/functions.tmdl</example><note>The functions in DAXLib are in TMDL. You should not use createorreplace and should instead follow the syntax rules in the example above, or in the microsoft documentation</note>
- dax.guide for dax functions <example>https://dax.guide/calculate/ for the `CALCULATE` function</example>
- sqlbi.com for dax concepts and theory
</references>
## Style
- Use concise bullet points and avoid verbose explanations
- Answer questions directly BEFORE any explanations
- Think step-by-step for complex problems and show your work
- Use `--` or `//` for all comments and not `#`
Note that the instructions are concise and well-structured, organizing the content into sections with headings (denoted by #) and XML tags (denoted by <tag> content </tag>) among other syntax. Writing good context is a valuable skill; don’t offload this to an AI.
You can also do this in Copilot in Power BI by means of instructions in a semantic model. Instructions let you tune Copilot’s responses and behavior; you can even use it to disable certain experiences like report summarization and DAX query generation, if you want.
Curate context into composable, re-usable context and prompts
In summary, to effectively use AI with DAX like UDFs, Power BI, or anything, generally… you need to provide sufficient context. You can do this in prompts, you can ask the agent to get context itself, or you can place it into persisting files that work like memory. However, the most effective method involves taking this context and putting it in a markdown file that you can reuse across not just sessions and prompts, but also tools, models, and scenarios. One way to do this is by using MCP server resources. A better way is by using agent skills and subagents. This might sound complex, but it’s not; it is simply a structured way of providing instructions, like the previous example. It’s about writing good markdown documents and reusing them in a structured and elegant way.
We’ll talk about this in a follow-up article.
How AI-generated DAX can cause problems
Even with all this context and structure, AI can still make mistakes. Instructions are not hard rules, and only incrementally increase the usefulness of outputs. AI can still ignore or go against your instructions; you cannot force an AI to follow instructions every session.
Consider the following example, which shows an AI-generated DAX function from Claude with Sonnet 4.5:
(
// The measure to calculate the moving average for
pMeasure: EXPR,
// Number of days in the moving average window
pDays: INT64
)
=>
VAR _DateColumn = 'Date'[Date]
VAR _Window =
WINDOW(
-(pDays - 1), REL,
0, REL,
ALLSELECTED(_DateColumn),
ORDERBY(_DateColumn, ASC)
)
VAR _Result =
IF(
COUNTROWS(_Window) = pDays,
AVERAGEX(_Window, CALCULATE(pMeasure))
)
RETURN
_Result
In this case, the function has several issues. First, columns can’t be assigned to variables, like how the Date column is assigned to the _DateColumn variable. For this function to be valid, it needs to either replace the variable in the expression with the Date column, or it should parameterize this, and use the parameter, instead. The correct function is below:
(
// The measure to calculate the moving average for
pMeasure: EXPR,
// Number of days in the moving average window
pDays: INT64,
// Date column
pDate: ANYREF
)
=>
VAR _Window =
WINDOW(
-(pDays - 1), REL,
0, REL,
ALLSELECTED(pDate),
ORDERBY(pDate, ASC)
)
VAR _Result =
IF(
COUNTROWS(_Window) = pDays,
AVERAGEX(_Window, pMeasure)
)
RETURN
_Result
However, there is still a problem. If we were to use this function in a model, it does work in some filter contexts. It produces the expected results. You can see this when comparing to a function written manually for validation:
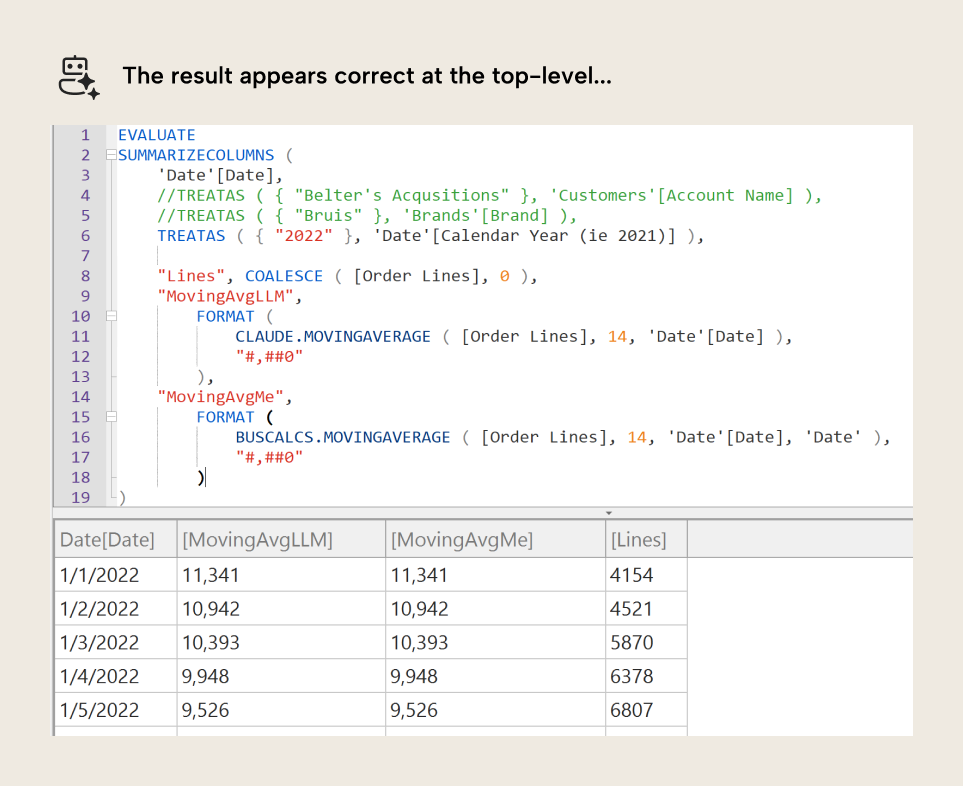
However, once you start filtering the model, you get unexpected results. For instance, if you filter to a single customer, there are days when that customer did not order anything. This means that the Order Lines measure in the example above would return blank on those dates. The AI-generated function doesn’t account for these edge cases (shown in MovingAvgLLM), while the validation function (shown in MovingAvgMe) does.
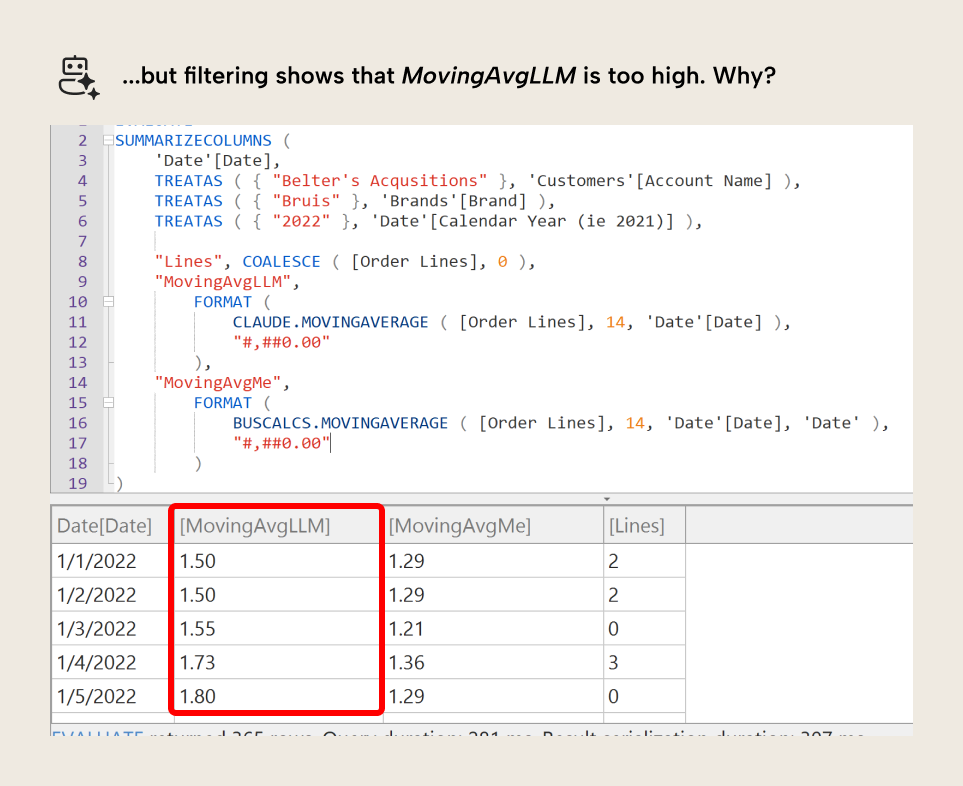
The reason for this is because the function generated by Claude filters out days with no sales. It doesn't consider the edge-case, and would thus be considered incorrect by users in our reports. We can circumvent that with critical thinking in follow-up prompts, by simply asking a follow-up question:
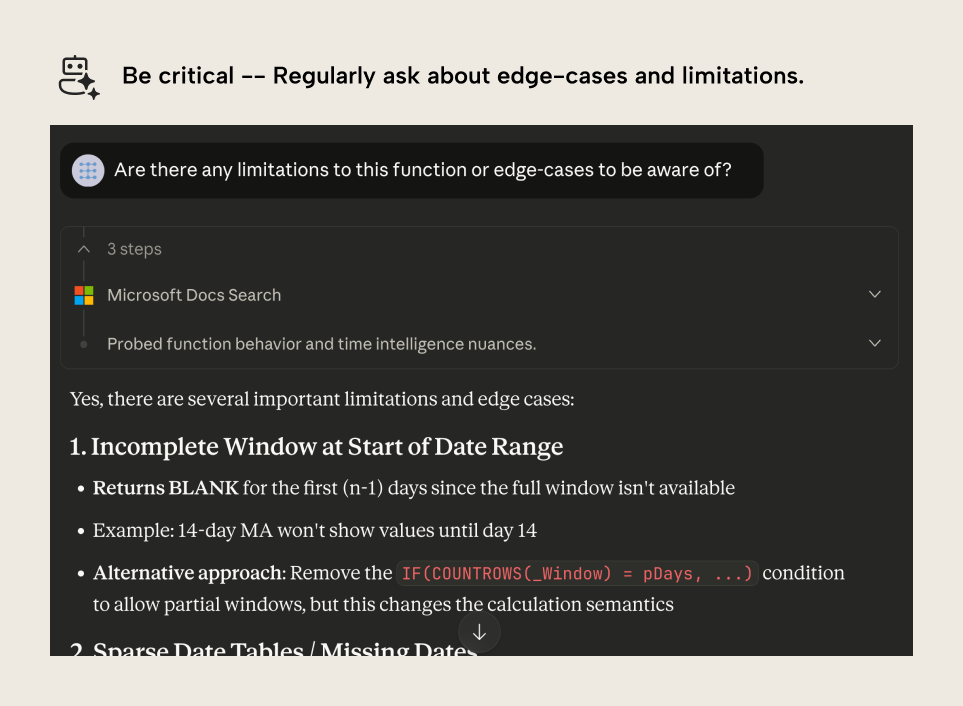
This might result in a different function, like the below:
// Calculate moving average over N periods
(
// Measure to average
measure_reference: EXPR,
// Number of periods
periods: INT64,
// Column for periods (e.g., Date column)
period_column: ANYREF,
// Table for periods (e.g., Date table)
period_table: ANYREF
) =>
-- Uses approach from Definitive Guide to DAX 2e P202
VAR _LastVisibleDate = MAX ( period_column )
VAR _NumberOfPeriods = periods
VAR _PeriodToUse =
FILTER (
ALL ( period_table ),
period_column > _LastVisibleDate - _NumberOfPeriods &&
period_column <= _LastVisibleDate
)
VAR _Result =
CALCULATE (
DIVIDE (
measure_reference, COUNTROWS ( VALUES ( period_column ) )
),
_PeriodToUse
)
RETURN
_Result
Note that asking such a follow-up question doesn't guarantee you will get better results. It is up to you as the author to assert your own critical thinking and scepticism, which may involve doing your own research and testing up-front.
In summary, applying context can help you get better initial results when using AI to help you with DAX or Power Query problems… or anything related to code. However, it doesn’t guarantee that the first working answer is the best (or even the correct) answer. It’s just one step on the way there.
For further reading
- DAX User Defined Functions (DAX UDFs) for Power BI in simple terms (Tabular Editor). Explains the anatomy of a UDF, including parameters, type hints, and the expression body, which is the foundation for the AI-assisted authoring workflows described here.
- 8 tips for writing User-Defined Functions in DAX (Tabular Editor). Covers naming, documentation, and testing practices that help ensure AI-generated code meets quality standards before use.
- User-defined functions in DAX (Microsoft). The official DAX UDF specification, including supported type hints and the evaluation rules that AI tools must adhere to when generating UDFs.
- Skills for Claude (Anthropic). Anthropic’s explanation of reusable instruction packages, which is relevant to the context-curation pattern described in this article.
In conclusion
Context curation is incredibly important, especially when you use AI with Power BI. Power BI has new formats like TMDL and PBIR, as well as massive new features like DAX functions and visual calculations. Relying on LLMs and prompts alone, even in Microsoft’s native tools like Copilot in Power BI, will not produce good results. You have to invest time and effort to create context, and then re-use it in an efficient way; AI might not be an objective accelerator at first (even if it seems so), until you get better at using it. However, even in the “ideal” scenario, you should understand that AI outputs are an incremental first step; just because the code is working doesn’t mean it’s correct.
Refactor DAX UDF patterns with AI and Tabular Editor 3 scripts.
Give Tabular Editor a spin