
Este contenido fue traducido mediante IA y no ha sido revisado por un editor humano. Las imágenes y los gráficos permanecen en su idioma original.
Conclusiones clave
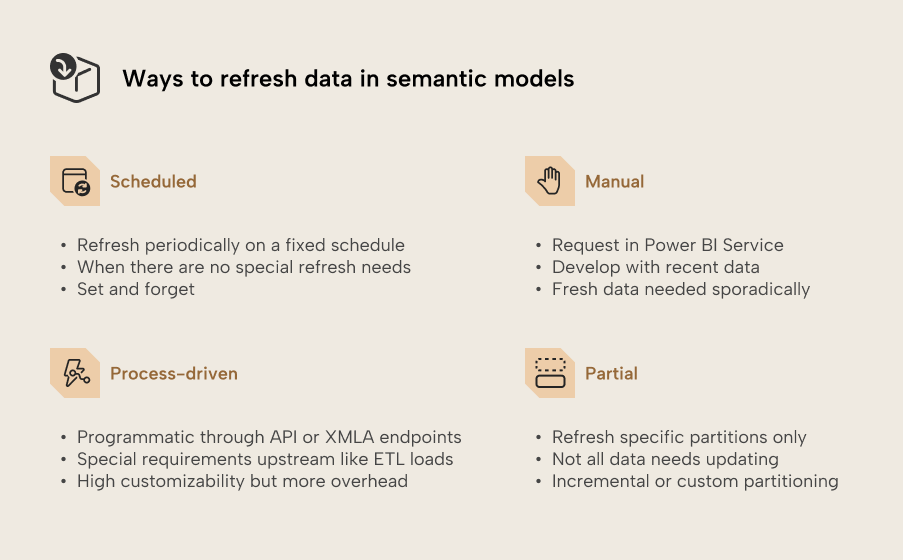
- Por lo general, Power BI funciona mejor con datos importados. Hay distintas opciones para mantener esos datos actualizados. Saber cuándo usar cada opción te ayudará a mantener el panorama de datos eficiente.
- La actualización programada es una opción práctica y flexible cuando no hay requisitos especiales. La actualización basada en procesos ofrece muchas opciones de personalización mediante la API y los puntos de conexión XMLA, a costa de cierta sobrecarga de configuración y mantenimiento.
- La actualización parcial puede reducir de forma significativa la cantidad de datos que hay que actualizar. La actualización incremental nativa funciona con particiones basadas en fechas, pero también es posible un particionado personalizado.
Este resumen lo elabora el autor, no la IA.
Los modelos semánticos son la columna vertebral de tu panorama de datos en Fabric. En esencia, son bases de datos que sirven datos a una variedad de aplicaciones: Report de Power BI, recursos de Fabric como cuadernos y exploraciones, pero también a libros de Excel y a otras aplicaciones a través de puntos de conexión de la API. De hecho, los datos que sirven deben ser precisos y relevantes.
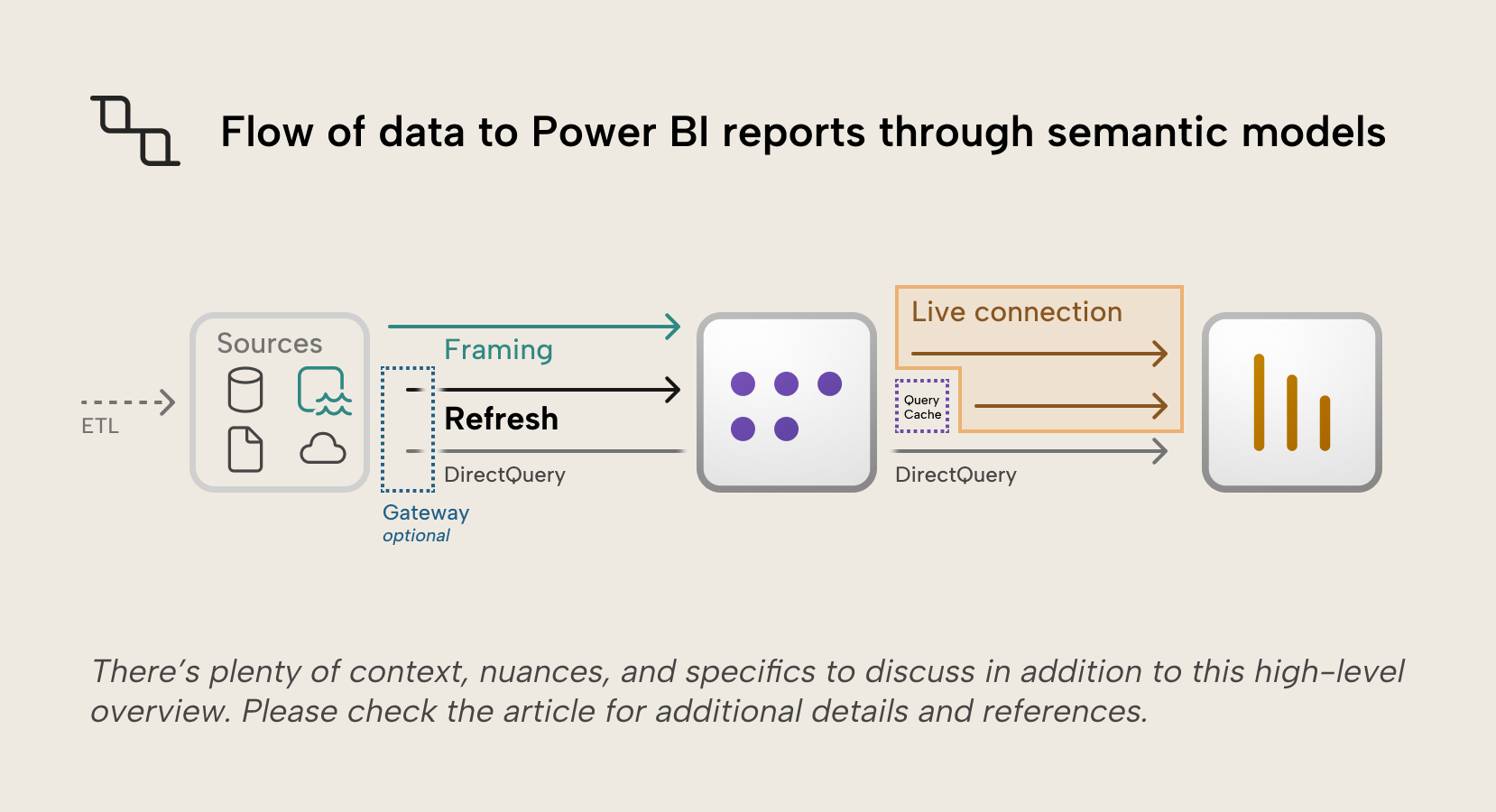
En un artículo anterior hablamos de los modos de almacenamiento para modelos semánticos de Power BI y mencionamos que el valor predeterminado preferido es el modo de almacenamiento de importación, en el que los datos de origen se actualizan periódicamente en memoria. Esas importaciones deben mantenerse actualizadas para garantizar que sean precisas y relevantes. Este artículo se centrará en la actualización de los datos almacenados en el modelo semántico, pero también tocará otros tipos de almacenamiento, como los resultados de consultas en caché y el concepto de framing en el modo de almacenamiento Direct Lake, ya que se relaciona con el concepto de cargar datos por lotes, igual que hace el modo de almacenamiento de importación. El procesamiento de datos en tiempo real merece su propio artículo, que quizá escribamos en el futuro.
Analizaremos las distintas formas de actualizar los datos desde una perspectiva general, más que desde los detalles técnicos, y enlazaremos recursos útiles cuando corresponda.
Actualización programada
Para modelos semánticos de importación sin necesidades especiales de actualización, los calendarios de actualización configurados en la configuración de los modelos semánticos publicados son la opción recomendada. La actualización programada es un mecanismo sencillo pero flexible, y lo más cercano a “configurar y olvidarte” para mantener actualizados los datos importados.
¿Cuándo usarla?
- Las Data sources tienen calendarios de carga predecibles.
- Los datos importados deben actualizarse cada pocas horas o días.
¿Dónde se configura?
- El propietario del modelo semántico puede definir calendarios en la interfaz de configuración del modelo semántico de los modelos publicados.
- Los calendarios también se pueden definir mediante el punto de conexión de la API, también por el propietario del modelo semántico.
¿Cuáles son los límites?
- La duración máxima depende de la capacidad del Workspace: 2 horas para Pro, 5 horas para Premium
- Las actualizaciones diarias dependen de la capacidad del Workspace: hasta 8 en Pro, hasta 48 en Premium
- Tipos de actualización compatibles: actualización automática de todo el modelo
- Parámetros de programación: un calendario puede tener varias horas que se aplican a todos los días de la semana seleccionados en el calendario.
- P. ej., Todos los días a las 07:00 → 1 vez, aplicada todos los días.
- P. ej., Lunes y jueves a las 07:30 y 14:30 → 2 veces, aplicadas en 2 días de la semana.
- P. ej., Lunes a las 07h30 y jueves a las 07h30 y 14h30 → no es posible porque las horas son distintas según el día de la semana. Las horas deben aplicarse a todos los días seleccionados.
NOTA
El tipo de actualización ‘automática’ recalculará tablas y columnas, y actualizará tablas y particiones según el estado de las particiones. Los otros tipos de actualización son clear, full, calculate, data only y defragment. Se pueden ejecutar con Tabular Editor y otras herramientas que admiten comandos XMLA o TMSL, como SQL Server Management Studio.
¿Qué debes tener en cuenta?
- Los calendarios se desactivarán automáticamente en algunos casos. Cuando esto ocurra, el propietario del modelo y los contactos recibirán una notificación por correo electrónico.
- Después de 2 meses de inactividad (es decir, sin uso posterior por Report u otros recursos).
- Después de 4 fallos consecutivos en la actualización programada.
- Después de un error de configuración, como credenciales caducadas.
- Distribuye los calendarios en el tiempo para evitar picos repentinos de carga en los sistemas de origen y en las capacidades de Fabric. Piensa cuándo se necesitan realmente datos recientes y deja que los calendarios sigan esos requisitos, teniendo en cuenta la duración típica de las actualizaciones.
- No está garantizado que la actualización empiece exactamente en el intervalo programado. Según la disponibilidad de la capacidad, una actualización programada puede empezar en cualquier momento entre 5 minutos antes y 1 hora después del intervalo programado.
ADVERTENCIA
La característica ‘actualización de OneDrive’ no debe confundirse con la actualización programada, ya que sincroniza el archivo desde OneDrive, pero no vuelve a cargar los datos desde los orígenes subyacentes. Para actualizar los datos desde los orígenes, sigue siendo necesaria una actualización programada o bajo demanda. Una actualización bajo demanda desencadenará tanto una sincronización del archivo como una actualización de datos.
Actualización manual
Como su nombre indica, una actualización manual se inicia cuando se solicita, haciendo clic manualmente en el botón ‘Actualizar’ en la interfaz de usuario. En la documentación de Microsoft, a menudo se denomina actualización bajo demanda. Las actualizaciones bajo demanda pueden solicitarse de forma manual o mediante programación. Estos métodos de solicitud tienen casos de uso y opciones de personalización diferentes, así que los tratamos por separado en este artículo.
¿Cuándo usarla?
- Probar desarrollos de funcionalidades para modelos semánticos de importación con datos recientes.
- Solo se necesitan datos recientes de forma esporádica, y la actualización se completa casi al instante.
¿Dónde se configura?
Si tienes permiso de ‘Escritura’ en el modelo semántico, puedes solicitar una actualización bajo demanda en la página de detalles del modelo.
¿Cuáles son los límites?
- La duración máxima depende de la capacidad del Workspace: 2 horas para Pro, 5 horas
- El número diario de solicitudes de actualización depende de la capacidad del Workspace: 8 en Pro (incluida la actualización programada), sin límite en Premium siempre que la capacidad tenga recursos disponibles.
- Tipos de actualización compatibles: actualización automática de todo el modelo
¿Qué debes tener en cuenta?
No puedes solicitar una actualización manual cuando ya hay una actualización en curso. Primero tienes que cancelar la actualización en curso antes de poder solicitar una nueva.
Actualización basada en procesos
A veces, tu modelo semántico solo debería actualizarse cuando haya finalizado un proceso, por ejemplo cuando las cargas ETL previas o las comprobaciones de calidad de datos se han completado correctamente. Un calendario fijo podría interferir con esos procesos si tardan más de lo habitual, y una actualización manual sencillamente no es escalable. En esos casos, una actualización bajo demanda solicitada por un proceso automatizado mediante la API o los puntos de conexión XMLA garantiza la sincronización. Estos puntos de conexión permiten la actualización mejorada con más opciones de personalización que las actualizaciones programadas o manuales.
¿Cuándo usarla?
- La actualización solo debe ocurrir cuando se cumplan ciertas condiciones, por ejemplo, cuando hayan finalizado las cargas de datos de origen y las comprobaciones de calidad se hayan completado correctamente.
- Deben actualizarse partes específicas del modelo, es decir, solo algunas tablas o particiones históricas. Esto no es posible con la actualización programada o manual.
¿Dónde se configura?
- En la aplicación o proceso que enviará las solicitudes a los puntos de conexión de API o XMLA. El punto de conexión de la API se adapta mejor que el punto de conexión XMLA para tareas de orquestación automatizada como esta, pero el punto de conexión XMLA ofrece un control más granular sobre las operaciones de actualización, por ejemplo para sobrescribir expresiones de sondeo.
- El token de autenticación pasado en el encabezado de la solicitud debe pertenecer a un usuario o entidad de servicio de aplicación con permiso de ‘Escritura’ en el modelo semántico.
¿Cuáles son los límites?
- El número de solicitudes de actualización depende de la capacidad del Workspace: 8 en Pro (incluida la actualización programada), sin límite en Premium siempre que la capacidad tenga recursos disponibles.
- La duración máxima depende de la capacidad del Workspace y del punto de conexión: 2 horas para Pro; para Premium 5 horas de forma predeterminada o hasta 24 horas (indicándolo como parámetro de tiempo de espera en la solicitud al punto de conexión de la API); y sin límite para actualizaciones mediante XMLA.
- El punto de conexión de la API está disponible para modelos en Workspaces Pro. El punto de conexión XMLA requiere que los modelos estén en un Workspace PPU, o en un Workspace asignado a una capacidad Premium o de Fabric.
- Actualización compatible: se admiten todos los tipos de actualización.
¿Qué debes tener en cuenta?
No puedes solicitar una actualización cuando ya hay una actualización en curso. Primero tienes que cancelar la actualización en curso antes de poder solicitar una nueva. Se puede solicitar la cancelación a través del punto de conexión de la API.
Actualización parcial
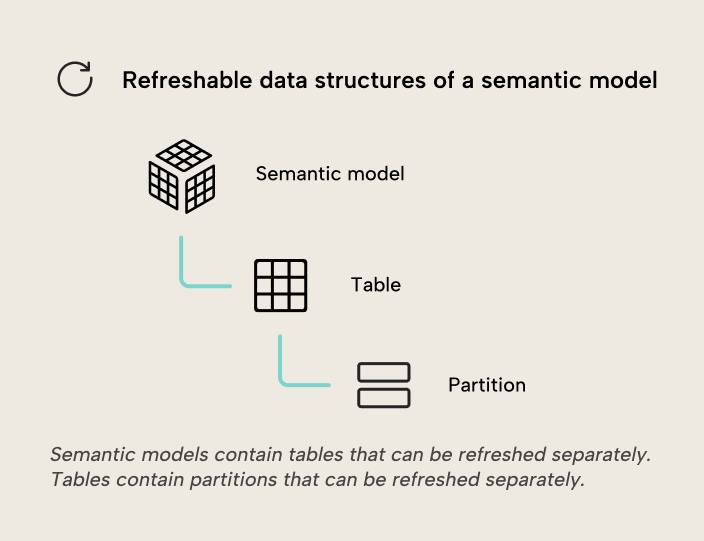
Los datos de origen no siempre cambian con frecuencia, así que puede tener sentido recargar solo lo que haga falta con una actualización parcial. Actualización incremental puede reducir de forma significativa la cantidad de datos que hay que actualizar, al recargar solo los datos nuevos o actualizados. Se puede configurar una política de actualización de actualización incremental para una tabla, y al actualizarse esa tabla se dividirá en particiones organizadas por granularidades de fecha (es decir, años, trimestres, meses o días) según la política. Cada partición puede actualizarse por separado. En cada actualización, las particiones se administrarán automáticamente, creando y cargando nuevas particiones, recargando particiones cuando los datos de origen se hayan actualizado y combinando particiones históricas.
También es posible particionar tablas por columnas que no sean de fecha. Particionado personalizado permite más flexibilidad que las particiones creadas automáticamente por las políticas de actualización incremental, a cambio de un mayor esfuerzo de administración.
¿Cuándo usarlo?
- No es necesario actualizar todos los datos con la misma programación.
- Los datos de origen que deben actualizarse pueden dividirse en particiones de forma fiable, por ejemplo mediante una columna de fecha para la actualización incremental u otras columnas para el particionado personalizado.
¿Dónde configurarlo?
- Establece la política de actualización incremental para la tabla del modelo semántico en Power BI Desktop, después publícala en Power BI Service y actualiza. Las particiones personalizadas no se pueden configurar en Power BI Desktop ni en la interfaz de usuario de Power BI Service.
- La política de actualización incremental y las particiones personalizadas se pueden configurar y aplicar en Tabular Editor y en otras herramientas que admiten comandos XMLA o TMSL, como SQL Server Management Studio.
¿Cuáles son los límites?
- La actualización parcial se basa en particiones y las particiones deben actualizarse por completo. No es posible realizar un “upsert”, es decir, actualizar solo las filas que se han modificado.
- Las eliminaciones “hard” (es decir, filas que se eliminan de la tabla de origen) no las detecta la actualización incremental y permanecerán en las particiones del modelo semántico. Las eliminaciones “soft”, en las que se actualiza la columna usada para detectar cambios en los datos, desencadenarán una recarga de la partición.
- Para la actualización incremental, el origen de datos debe filtrarse por una fecha. Los parámetros de filtrado RangeStart y RangeEnd deben pasarse a las consultas al origen.
- La actualización incremental es compatible con los Workspaces Pro. Actualizar particiones históricas y administrar particiones personalizadas a través del punto de conexión XMLA requiere que los modelos estén en un Workspace PPU o en un Workspace asignado a una capacidad Premium o a una capacidad de Fabric.
¿En qué hay que fijarse?
- Si las actualizaciones de datos históricos son frecuentes y se reparten en el tiempo, la actualización incremental a menudo tendrá que recargar muchas particiones. Comprueba que la tabla de origen candidata sigue el patrón de actualización transaccional (se anexan filas nuevas; las antiguas rara vez se actualizan) antes de aplicar una política de actualización incremental.
- Las políticas de actualización incremental y las particiones personalizadas son otra configuración que hay que administrar y entender. En tablas con volúmenes moderados, la mejora de rendimiento puede ser limitada en relación con la sobrecarga técnica.
Almacenamiento en caché de consultas
El almacenamiento en caché de consultas guarda los resultados de las consultas para las páginas de destino de los Reports, para que los Visuals se muestren más rápido. Esta característica está disponible para modelos semánticos de importación en capacidades Premium o Embedded, y las cachés se actualizarán después de una actualización solicitada desde la interfaz (programada o manual bajo demanda). Las actualizaciones solicitadas a través de la API o de los puntos de conexión XMLA no actualizarán automáticamente las cachés de consultas.
Encuadre en Direct Lake
En el modo de almacenamiento Direct Lake, los datos se cargan en el motor VertiPaq del modelo semántico. Al igual que en Import mode, las consultas se ejecutan sobre columnas en memoria. Sin embargo, la forma en que los datos llegan al motor VertiPaq es distinta: en lugar del proceso de importación y actualización, Direct Lake usa la transcodificación de columnas para cargar columnas Parquet directamente desde OneLake en VertiPaq. Direct Lake es un tema amplio que ya hemos tratado, pero lo relevante para el tema de la actualización de datos es el concepto de encuadre. El encuadre controla qué versión de los datos ve el modelo semántico. Un marco es, básicamente, un puntero a una instantánea de un momento concreto basada en el registro de transacciones de la tabla Delta, similar a cómo el modo Import captura los datos tal y como existían en un momento concreto.
Conclusión
Hay distintas formas de mantener actualizados los datos importados en Power BI. Comprenderlas te ayudará a elegir el enfoque adecuado y, con ello, a mantener el panorama de datos eficiente y al día.
La actualización programada es una opción práctica si no hay requisitos especiales. Si los hay, la actualización basada en procesos ofrece un sinfín de opciones de personalización y la actualización parcial puede reducir la cantidad de datos que hay que actualizar, a cambio de una mayor sobrecarga de administración. Recuerda que las consultas en caché también deben actualizarse, y aprovecha el encuadre en Direct Lake para seleccionar qué marco de datos recientes se adapta mejor al consumo.


