
此内容由人工智能翻译,尚未经过人工编辑审核。图像和图表保持其原始语言。
关键要点
- Power BI 通常与导入数据配合效果最佳。 你可以通过不同方式让这些数据保持最新。 了解何时该用哪种选项,将帮助你保持数据体系高效。
- 在没有特殊要求时,计划刷新是方便且灵活的选择。 流程驱动刷新可以通过 API 和 XMLA endpoint 提供很强的自定义能力,但会带来一些额外的配置与维护成本。
- 部分刷新可以显著减少需要刷新的数据量。 原生的增量刷新适用于基于日期的分区,但你也可以选择自定义分区。
本摘要由作者撰写,并非由 AI 生成。
语义模型是你在 Fabric 数据体系中的基石。 本质上,它们就是数据库,为多种应用提供数据:Power BI 报表、Fabric 资产(如笔记本和探索),并通过 API 端点向 Excel 工作簿和其他应用提供数据。 因此,它们所提供的数据必须准确且具备业务相关性。
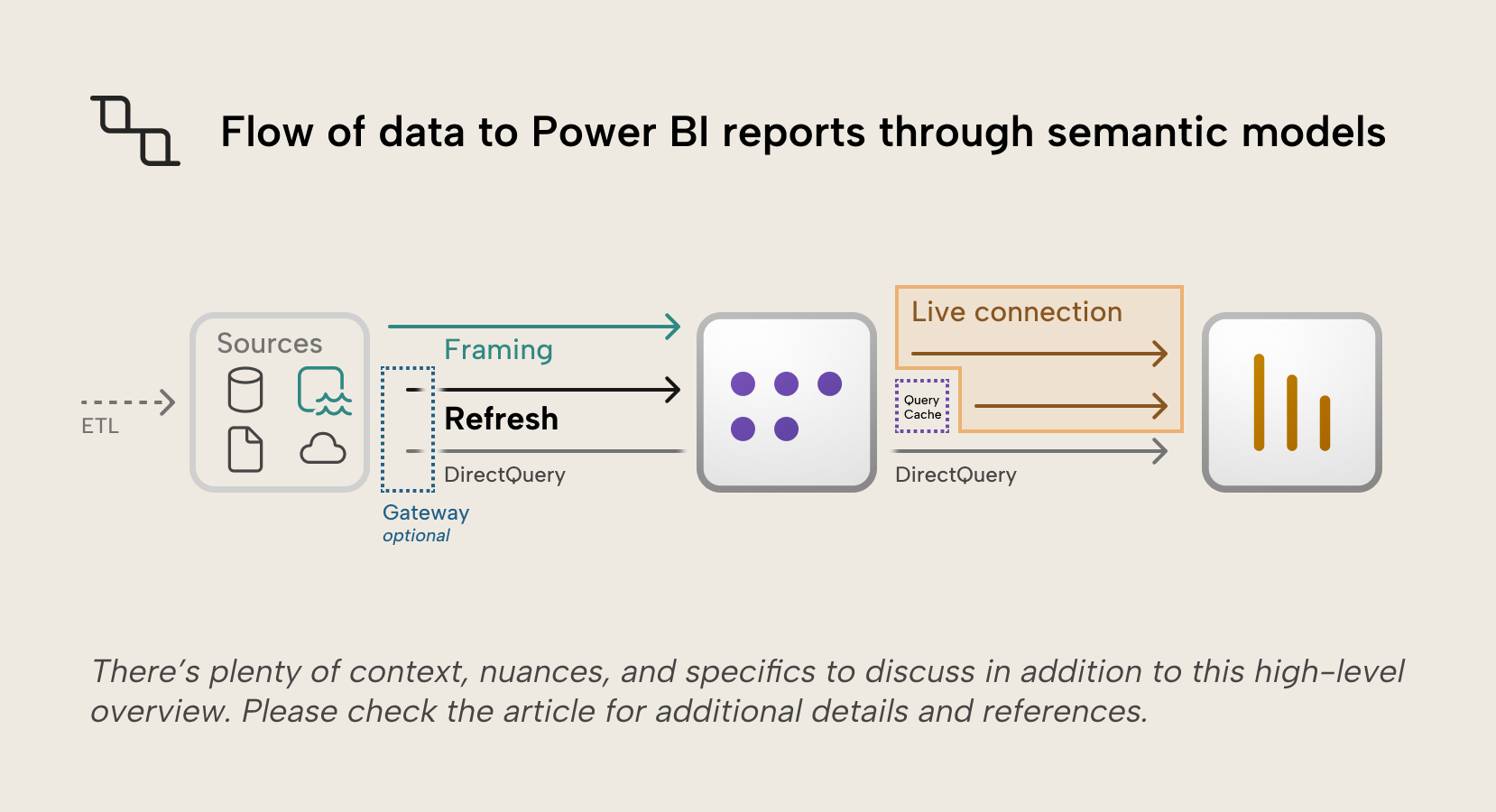
在之前的一篇文章中,我们讨论了 Power BI 语义模型的存储模式,并提到首选的默认模式是导入存储模式:源数据会定期刷新到内存中。 这些导入的数据必须保持最新,才能确保其准确且具备相关性。 本文将重点介绍如何刷新语义模型中存储的数据,同时也会提及其他存储内容,例如缓存的查询结果,并介绍 Direct Lake 存储模式中的 framing“框定”概念——因为它同样与“分批加载数据”的思路相关,类似导入存储模式。 实时数据处理值得单独写一篇文章,我们未来可能会展开。
我们将从概览的透视角度讨论数据刷新的不同方式,而不是深入技术细节,并在合适的地方提供相关的参考资源链接。
计划刷新
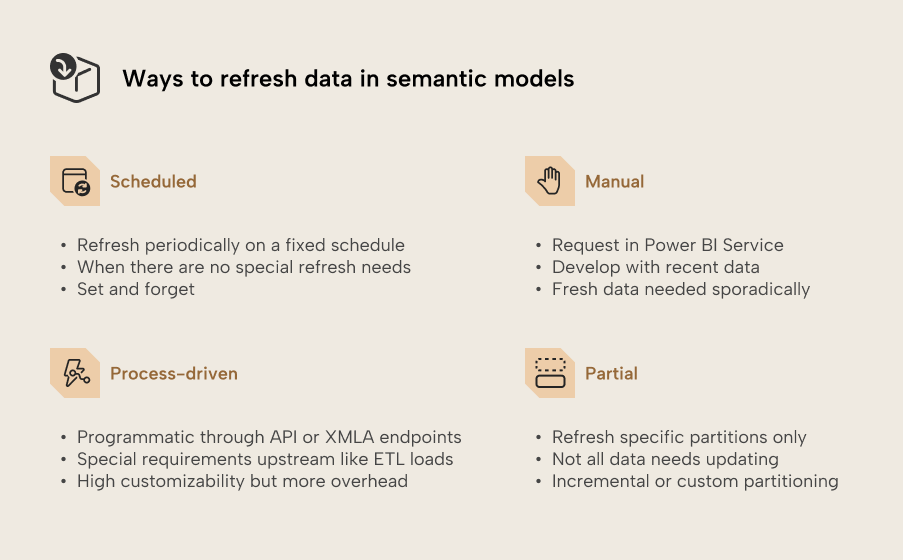
对于没有特殊刷新需求的导入语义模型,可以用已发布语义模型设置里配置的刷新计划。 计划刷新是一种简单但灵活的机制,用于保持导入数据更新,几乎可以做到“设置好就不用操心”。
何时使用?
- 数据源有可预测的加载周期。
- 导入数据需要每隔几小时或几天更新一次。
在哪里配置?
有哪些限制?
- 最长持续时间取决于 Workspace 容量:Pro 为2 小时,Premium 为5 小时
- 每日刷新次数取决于 Workspace 容量:Pro 最多8 次,Premium 最多48 次
- 支持的刷新类型:整个模型的自动刷新
- 计划参数:一个计划可以包含多个时间点,并会应用到该计划中选定的所有星期几。
- 例如。 每天 07:00 → 1 个时间点,应用于每天。
- 例如。 周一和周四在 07h30 和 14h30 → 2 次,应用于每周 2 天。
- 例如。 周一 07h30,周四 07h30 与 14h30 → 不可行,因为不同星期几的时间点不一致。 时间点必须在所有选定的日期中一致适用。
注意
“automatic” 刷新类型会重新计算表和列,并根据分区状态刷新表和分区。 其他刷新类型包括 clear、full、calculate、data only 和 defragment。 这些操作可以使用 Tabular Editor 执行,也可以通过支持 XMLA 或 TMSL 命令的其他工具来执行,例如 SQL Server Management Studio。
需要注意什么?
- 在某些情况下,计划会自动停用。 发生这种情况时,模型所有者和联系人会收到邮件通知。
- 在连续 2 个月无活动后(即 Report 或其他下游资产没有使用)。
- 在连续 4 次计划刷新失败后。
- 在出现配置错误后,例如凭据过期。
- 将计划分散到不同时间点,避免源系统和 Fabric capacity 出现突发负载峰值。 请根据实际需要获取最新数据的时间来安排计划,并考虑刷新通常所需的时长。
- 无法保证刷新会在计划的确切时间段开始。 根据容量可用情况,计划刷新可能会在预定时间段开始前 5 分钟至开始后 1 小时之间的任意时刻启动。
警告
请勿将“OneDrive 刷新”与计划刷新混淆:它只会从 OneDrive 同步文件,但不会从底层数据源重新加载数据。 要从数据源刷新数据,仍然需要计划刷新或按需刷新。 按需刷新会同时触发文件同步和数据刷新。
手动刷新
顾名思义,手动刷新会在用户在界面中手动点击“刷新”按钮时启动。 在 Microsoft 文档中,这通常被称为按需刷新。 按需刷新可以通过手动或编程方式发起。 这些发起方式的适用场景和可自定义选项不同,因此我们会在本文中分别介绍。
何时使用?
- 用最新数据测试导入语义模型的功能开发。
- 仅偶尔需要最新数据,且刷新几乎瞬间完成。
在哪里配置?
任何拥有语义模型“写入”权限的用户,都可以在模型详情页发起按需刷新。
有哪些限制?
- 最长持续时间取决于 Workspace 容量:Pro 为 2 小时,Premium 为 5 小时
- 每天可发起的刷新次数取决于 Workspace 容量:Pro 为 8 次(包含计划刷新);Premium 在容量资源充足时不受限制。
- 支持的刷新类型:整个模型的自动刷新
需要注意什么?
当刷新已在进行中时,无法发起手动刷新。 必须先取消正在进行的刷新,才能发起新的刷新。
流程驱动刷新
有时,你的语义模型最好只在某个流程完成后再刷新,例如上游 ETL 加载或数据质量检查成功完成之后。 如果这些流程偶尔耗时比平时更长,固定计划可能会干扰它们;而手动刷新也不具备可扩展性。 在这种情况下,通过 API 或 XMLA endpoint 由自动化流程发起按需刷新,可以确保同步。 这些端点支持增强型刷新,可提供比计划刷新或手动刷新更多的自定义选项。
何时使用?
- 只在满足特定条件时才应刷新,例如源数据加载完成且质量检查成功。
- 只刷新模型的特定部分,例如仅刷新部分表或历史分区。 这在计划刷新或手动刷新中无法实现。
在哪里配置?
- 在会向 API 或 XMLA 端点发送请求的应用或流程中。 对于这类自动化编排任务,API 端点通常比 XMLA endpoint 更合适;但 XMLA endpoint 能对刷新操作提供更细粒度的控制,例如覆盖轮询表达式。
- 请求标头中传入的身份验证令牌,必须由拥有语义模型“写入”权限的用户或应用服务主体来使用。
有哪些限制?
- 可发起的刷新次数取决于 Workspace 容量:Pro 为 8 次(包含计划刷新);Premium 在容量资源充足时不受限制。
- 最长持续时间取决于 Workspace 容量和端点:Pro 为 2 小时;Premium 默认 5 小时,或可延长至24 小时(在发往 API 端点的请求中指定 timeout 参数);并且对 XMLA 刷新不设上限。
- API 端点可用于 Pro Workspace 中的模型。 XMLA endpoint 要求模型位于 PPU Workspace,或位于分配到 Premium 或 Fabric capacity 的 Workspace 中。
- 支持的刷新:支持所有刷新类型。
需要注意什么?
当刷新已在进行中时,无法发起刷新请求。 必须先取消正在进行的刷新,才能发起新的刷新。 可通过 API 端点 发起取消请求。
部分刷新
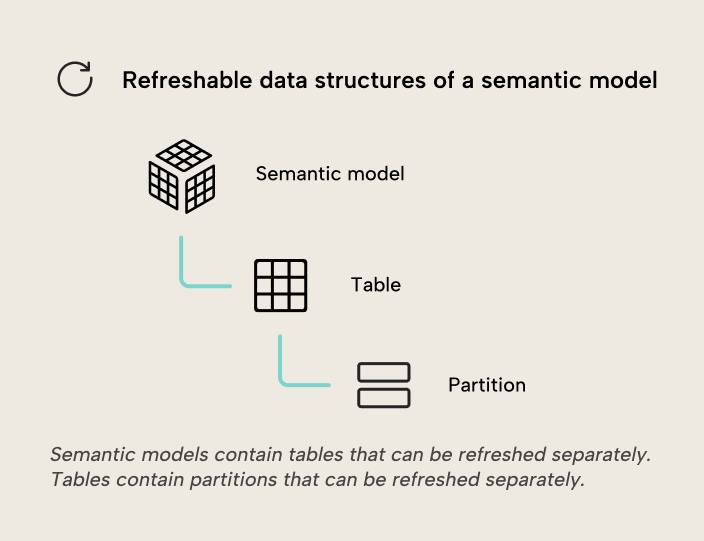
源数据并不总是频繁变化,因此使用部分刷新只重新加载需要重新加载的数据,往往更合理。 增量刷新 可以只重新加载新增或更新的数据,从而显著减少需要刷新的数据量。 你可以为某个表配置增量刷新的刷新策略;刷新时,该表会按照该刷新策略按日期粒度(即年、季度、月或日)拆分为多个分区。 这样每个分区就可以分别刷新。 每次刷新时,系统都会自动管理分区:创建并加载新分区;当源数据更新时重新加载相应分区;并合并历史分区。
也可以选择按非日期列对表进行分区。 自定义分区 相比增量刷新的刷新策略自动创建的分区更灵活,但代价是需要更多管理开销。
何时使用?
- 并非所有数据都必须按同一计划刷新。
- 需要刷新的源数据能够可靠地进行分区,例如增量刷新时按日期列分区,或自定义分区时按其他列分区。
在哪里配置?
- 在 Power BI Desktop 中为语义模型的表设置增量刷新的刷新策略,然后发布到 Power BI Service 并刷新。 无法在 Power BI Desktop 或 Power BI Service 的用户界面中配置自定义分区。
- 增量刷新策略和自定义分区可以在 Tabular Editor 以及其他支持 XMLA 或 TMSL 命令的工具(例如 SQL Server Management Studio)中配置并应用。
有哪些限制?
- 部分刷新是以分区为基础,且分区必须整体刷新。 无法进行“upsert”,也就是只刷新已更新的行。
- “硬” 删除 (即源表中被删除的行) 不会被增量刷新检测到,并将继续保留在语义模型的分区中。 如果是“软”删除,且用于检测数据更改的列被更新,将触发对该分区的重新加载。
- 对于增量刷新,数据 源必须按日期进行筛选。 RangeStart 和 RangeEnd 这两个筛选参数 必须传递到针对数据源的查询中。
- 增量刷新在 Pro 工作区中受支持。 通过 XMLA endpoint 刷新历史分区并管理自定义分区,要求模型位于 PPU Workspace,或位于分配给 Premium 或 Fabric capacity 的 Workspace 中。
需要注意什么?
- 如果历史数据的更新很常见且分散在不同时间段,增量刷新可能经常需要重新加载许多分区。 在应用增量刷新策略之前,请先验证候选源表是否符合事务型更新模式 (新增行追加写入,旧行很少更新)。
- 增量刷新策略和自定义分区是需要额外管理并理解的另一项配置。 对于数据量不大的表,性能提升相对于技术管理开销可能并不明显。
查询缓存
查询缓存会为报表着陆页缓存查询结果,使视觉对象渲染更快。 此功能适用于 Premium 或 Embedded 容量中的导入语义模型;通过界面发起的刷新请求(计划刷新或手动按需刷新)完成后,缓存也会随之刷新。 通过 API 或 XMLA endpoint 发起的刷新请求不会自动刷新查询缓存。
Direct Lake 框定
在 Direct Lake 存储模式下,数据会被加载到语义模型的 VertiPaq 引擎中。 与 Import mode 一样,查询会针对内存中的列运行。 不过,数据进入 VertiPaq 引擎的方式不同:Direct Lake 不通过导入和刷新流程,而是使用列转码 column transcoding 将 OneLake 中的 Parquet 列直接加载到 VertiPaq。 Direct Lake 是个很深的话题,我们之前也介绍过;但在数据刷新这个主题里,关键是 Framing 这个概念。 Framing 决定语义模型看到的是哪个版本的数据。 Frame 本质上是一个指针,指向基于 Delta Table 事务日志的某个特定时间点快照,类似于导入存储模式会捕获某个时间点的数据状态。
总结
让导入到 Power BI 的数据保持最新,有多种方式。 理解这些方式能帮助你选择合适的方案,从而让数据环境更高效、更新更及时。
如果没有特殊要求,计划刷新是一个方便的选择。 如果有特殊要求,那么流程驱动的刷新提供了丰富的自定义选项;而部分刷新可以减少需要刷新的数据量,但需要额外的管理开销。 别忘了缓存的查询也需要刷新;此外,在 Direct Lake 中善用 Framing,选择最适合使用的近期数据帧。


