
Este contenido fue traducido mediante IA y no ha sido revisado por un editor humano. Las imágenes y los gráficos permanecen en su idioma original.
Puntos clave
- La IA puede consultar o modificar modelos semánticos. Los sistemas de IA capaces de usar herramientas para interactuar con modelos semánticos son agentes. Los agentes que leen y consultan modelos semánticos solo facilitan la BI conversacional y la exploración de datos respondiendo a preguntas de los usuarios sobre los datos (como Copilot o los agentes de datos en Microsoft Fabric). Los agentes que modifican modelos semánticos usan herramientas para cambiar los metadatos del modelo, ya sea directamente o de forma programática.
- El desarrollo agéntico puede ser útil para los modelos semánticos. Los agentes pueden ayudarte a ahorrar tiempo y quebraderos de cabeza cuando los aplicas en los escenarios adecuados y con una preparación cuidadosa. Sin esa preparación o en escenarios inadecuados, el uso de agentes puede no mejorar el tiempo de desarrollo ni la calidad, e incluso puede aumentar el tiempo y el coste de desarrollo. También debes tener en cuenta las advertencias, limitaciones y preocupaciones de seguridad de los datos al usar esta tecnología.
- Los agentes de codificación como Claude Code ofrecen los casos de uso más interesantes. Sin agentes de codificación, aun así puedes usar Copilot en Power BI o llamar a APIs desde código para usar IA con un modelo semántico. Sin embargo, están surgiendo escenarios mucho más interesantes y útiles con agentes de codificación como GitHub Copilot, especialmente los que se ejecutan en una terminal, como Claude Code.
- Los agentes de codificación pueden modificar un modelo semántico de tres formas distintas. Pueden modificar directamente los metadatos del modelo, pueden usar servidores MCP de modelos semánticos o pueden usar herramientas y bibliotecas de línea de comandos directamente. Cada enfoque tiene ventajas y desventajas, y si estás haciendo desarrollo agéntico, probablemente usarás una combinación de los tres para complementar los flujos de trabajo de desarrollo tradicionales.
- Esta serie de artículos explora el desarrollo agéntico de modelos semánticos. Examinaremos cada enfoque en detalle y comentaremos las distintas ventajas y desventajas. Aunque estos artículos se centran en modelos semánticos, los conceptos subyacentes también se aplican al desarrollo agéntico de otros artefactos (como Reports) y, en general, al desarrollo agéntico de software.
Este resumen lo ha elaborado el autor, no una IA.
Uso de agentes de IA con modelos semánticos
Desde la aparición de ChatGPT, ha habido interés en usar IA para ayudar a escribir DAX y crear modelos semánticos. Antes, esto se limitaba a copiar y pegar código desde un chatbot, usar Copilot en Power BI o llamar a APIs desde scripts y cuadernos. Ahora, la llegada de agentes de codificación como Claude Code de Anthropic hace que esto sea mucho más interesante y viable. Los agentes de codificación son sistemas de IA en los que el modelo de lenguaje de gran tamaño (LLM) puede generar y ejecutar código usando herramientas en un bucle.
En el contexto de un modelo semántico, un agente puede definirse de una de estas dos maneras:
- Agentes que consultan modelos semánticos: Exploran metadatos y generan consultas contra el modelo para recuperar información y responder a preguntas de datos de los usuarios. Normalmente a esto lo llamamos BI conversacional, en contraste con la BI tradicional, donde los usuarios ven datos en Visuals o en tablas a partir de consultas al modelo. Un ejemplo de un agente de consumo podrían ser las experiencias de Copilot de “hacer preguntas sobre los datos”, o los agentes de datos sobre modelos semánticos en Microsoft Fabric.
- Agentes que modifican modelos semánticos: Leen y modifican los metadatos del modelo semántico, ya sea directamente o de forma programática, e interactúan con el entorno que rodea al modelo semántico. A esto lo llamamos desarrollo agéntico de modelos semánticos. Ese tipo de agente no solo podría modificar propiedades y generar expresiones DAX o Power Query, sino también descargar, implementar y administrar modelos semánticos. Los agentes que pueden modificar modelos semánticos normalmente también pueden consultarlos; por ejemplo, puedes consultar un modelo semántico con cualquier agente de codificación (como Claude Code), pero aquí la consulta del modelo suele hacerse para fundamentar o validar cambios concretos.
En esta serie de artículos nos centramos en agentes para el desarrollo de modelos semánticos. En concreto, nos centramos en el panorama actual de herramientas y enfoques, y hablamos de los posibles casos de uso, beneficios y puntos a tener en cuenta de cada uno.
Es más fácil mostrar qué es un agente que explicarlo. Para ilustrarlo, aquí tienes un ejemplo de Claude Code realizando cambios en un modelo semántico en un entorno controlado. En concreto, está refactorizando medidas del modelo para usar una función DAX y cambiando el nombre de esas medidas para seguir unas convenciones estándar de nomenclatura:
En la demostración, el agente tiene acceso a metadatos del modelo local, un servidor MCP de Power BI y el Tabular Editor CLI para ejecutar C# Scripts contra modelos semánticos. Puede buscar en el modelo para encontrar medidas que refactorizar, leer la función que debe usar para entender su sintaxis y luego modificar el DAX de todas las medidas, que un usuario puede validar después. Refactorizar DAX así es un ejemplo de un caso de uso útil para el desarrollo agéntico de modelos.
NOTA
No eliges entre enfoques con IA y sin IA para el consumo o el desarrollo de un modelo semántico. Más bien, usas ambos, eligiendo el enfoque adecuado para un problema o escenario concreto. Normalmente (al menos ahora mismo) usas enfoques de IA para complementar tus flujos de trabajo existentes si pueden respaldarlo.
Si quieres entender los distintos escenarios en los que puedes aprovechar la IA y el desarrollo agéntico de forma más amplia, el autor lo ha explicado en detalle en SQLBI. Consulta este artículo y este documento técnico.
¿Qué es el desarrollo agéntico de un modelo semántico?
Esto significa que un agente tiene acceso a herramientas para ver y modificar los metadatos del modelo. Puede leer los nombres, expresiones y otras propiedades de tablas, columnas, medidas DAX y otros objetos. El agente puede crearlos, modificarlos o incluso eliminarlos. Normalmente, las herramientas que usa el agente para hacer esto permiten que el LLM genere valores de propiedades, como el nombre de una carpeta de visualización o la descripción de una medida.
El siguiente diagrama muestra, en términos sencillos, cómo es este proceso:
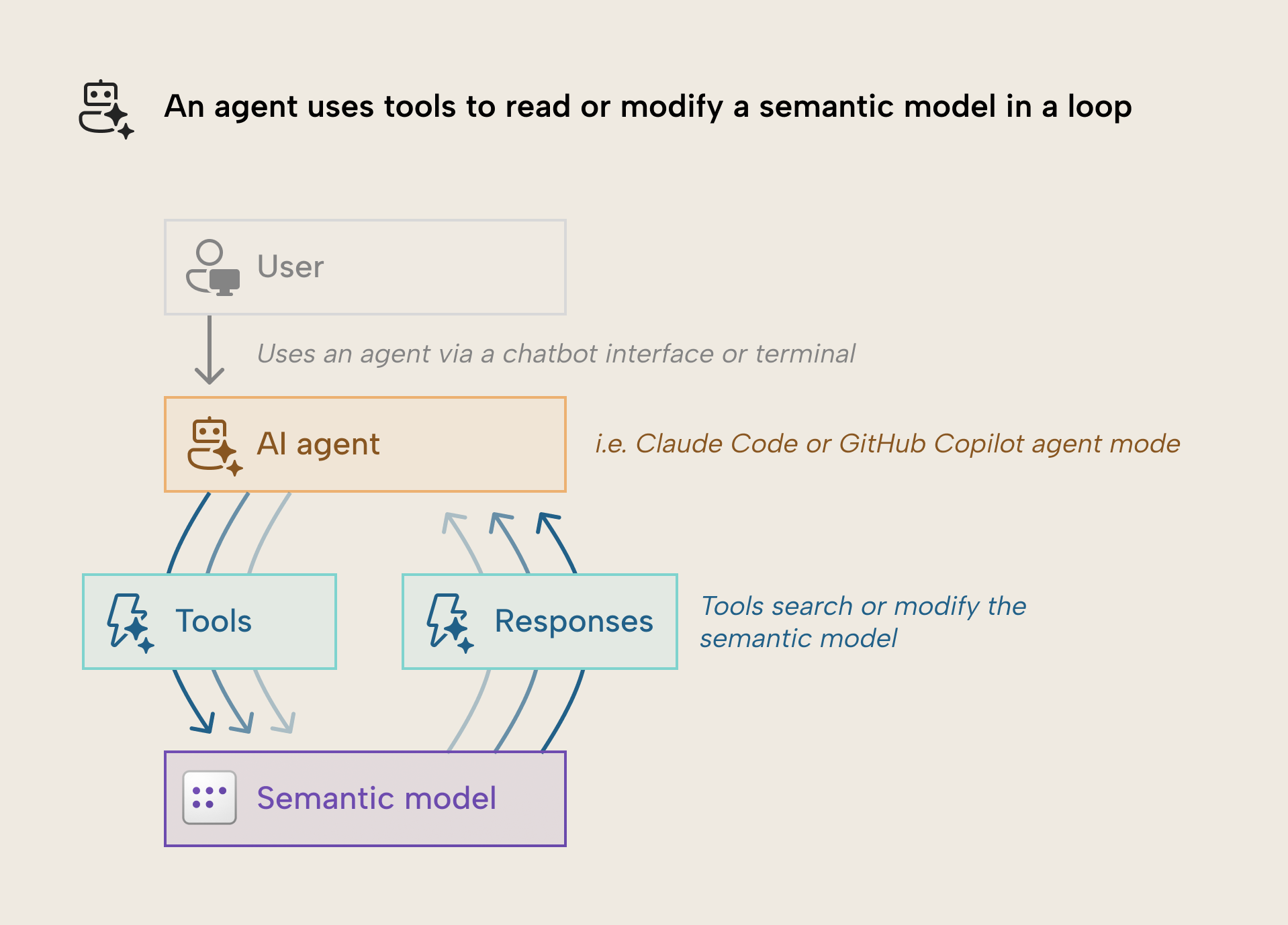
El proceso es el siguiente:
- Un usuario proporciona un prompt, indicando al agente que haga algo con el modelo semántico, normalmente a través de una interfaz de chatbot.
- El agente incorpora algún tipo de contexto, como otros archivos, el historial de la conversación y su prompt del sistema. Lo más habitual es que esto adopte la forma de archivos markdown en tu equipo que escribes tú y que el agente lee al inicio de una sesión o durante ella.
- El agente usa sus herramientas en un bucle para interactuar con el modelo semántico y lee las respuestas de las herramientas. El agente puede hacer varias llamadas a herramientas a la vez o (según el sistema) en paralelo.
- Con el tiempo, el agente sale del bucle de llamadas a herramientas y devuelve un resultado al usuario, que luego puede validar en una herramienta cliente como Tabular Editor, Power BI Desktop o VS Code.
Veremos cómo puede hacerlo el agente, pero primero analicemos por qué el desarrollo agéntico podría ser útil.
¿Por qué y cuándo harías desarrollo agéntico?
En teoría, puedes usar un agente para desarrollar y administrar un modelo semántico completo, de extremo a extremo. De hecho, esto ya es posible desde la llegada de los agentes de codificación a principios de este año, como comentamos y demostramos en un artículo anterior. De hecho, la novedad de usar lenguaje natural para ejecutar acciones en un entorno es, sin duda, tan impresionante como emocionante.
Sin embargo, el desarrollo agéntico es más útil y eficiente (tanto en coste como en tiempo) cuando lo aplicas de forma situacional. Aquí tienes varias razones para esto:
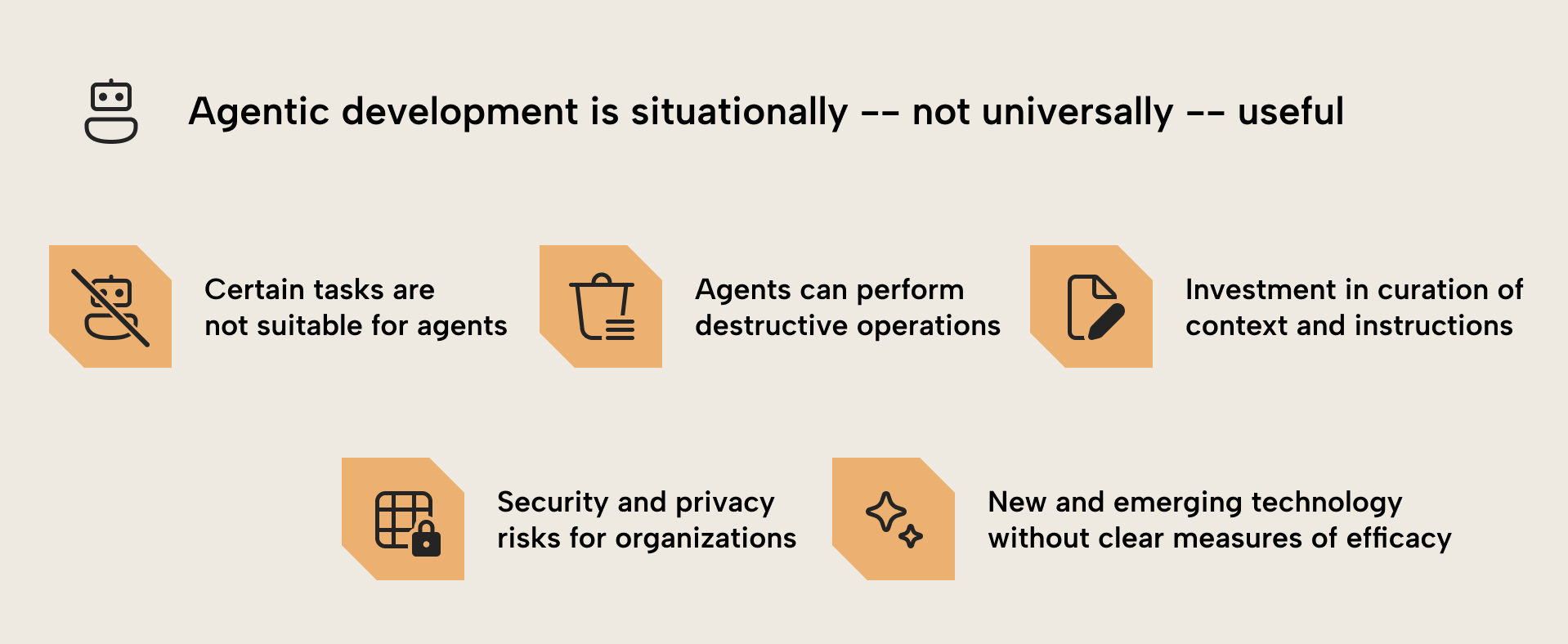
- Los agentes son mejores en algunas tareas que en otras. Por ejemplo, pueden ser bastante buenos refactorizando código, pero menos buenos generando código o metadatos sensibles a los espacios en blanco, p. ej., documentos TMDL.
- Los agentes pueden realizar operaciones destructivas. Cambiar, mover o eliminar incluso una sola medida en un modelo semántico puede romper Reports, molestar a los usuarios y hacerte perder tiempo. Al usar agentes, debes asegurarte de que gestionas diligentemente el control de código fuente, los puntos de control, las pruebas automatizadas y los permisos del agente para evitar accidentes.
- Para rendir bien, los agentes requieren instrucciones detalladas e información sobre una tarea. Necesitas invertir bastante tiempo en escribir este contexto en archivos de instrucciones para el agente, y no hay garantía de que ese coste genere un retorno de la inversión; es decir, un desarrollo más rápido o de mayor calidad. Hacer que la IA escriba este contexto por ti tampoco funciona de forma fiable; a menudo incluso conduce a peores resultados.
- Los agentes de codificación y los LLM en general conllevan diversos riesgos de seguridad y privacidad de datos para las organizaciones. La mayoría de los agentes gratuitos/públicos están sujetos a condiciones que podrían no alinearse con las políticas de privacidad y seguridad de datos de muchas organizaciones. A menos que tengas una suscripción empresarial validada por tu empleador y aprobada para usarse con los datos de tu organización, deberías limitar tu trabajo a tratar solo con datos y metadatos no sensibles. Esto es especialmente cierto para los consultores que buscan usar agentes de codificación para facilitar el trabajo con clientes sobre sus datos o metadatos.
- Esta es una tecnología incipiente (nueva y emergente). Muchos todavía están intentando averiguar los mejores enfoques para que los agentes funcionen bien, reduzcan costes y mitiguen riesgos. Hay pocas prácticas recomendadas y el ritmo y el volumen de cambios son altos. Peor aún, el rendimiento de los agentes es muy difícil de medir para tareas específicas. Los benchmarks son, en gran medida, indicadores poco matizados para comparar modelos por sí solos, y no tienen en cuenta otros factores (prompt, contexto, herramientas y entorno). Muchas de estas pruebas “carecen de rigor científico” y quizá no sean útiles ni fiables para su aplicación en el mundo real.
Ten en cuenta que las advertencias anteriores no son necesariamente razones para descuidar o rechazar el desarrollo agéntico por completo. Al contrario, conviene tenerlas presentes para que puedas aprovechar al máximo esta tecnología y, al mismo tiempo, mitigar sus riesgos. Hay muchas maneras en que el desarrollo con agentes puede ser beneficioso. Estos son algunos ejemplos de casos de uso en los que usar un LLM con tu modelo semántico puede tener sentido:

NOTA
Queremos destacar casos de uso en los que creemos que los LLM pueden mejorar los enfoques existentes (no basados en IA) para abordar determinados problemas. Estas mejoras pueden deberse tanto a las fortalezas del enfoque con LLM como a la comodidad para el usuario, pero solo cuando se sopesan frente a riesgos y salvedades realistas.
- Ayudarte a buscar o resumir partes de un modelo: Cuando trabajas con un modelo creado por otra persona, puede ser difícil “desenredar el código espagueti”. Usar un modelo eficiente como Haiku 4.5 puede ser una buena forma de ayudarte a encontrar determinados objetos, patrones o problemas (en lugar de otro modelo como Sonnet 4.5, ya que se sabe que Haiku 4.5 es más rápido y eficiente en búsquedas y resúmenes). Algunos ejemplos:
- Encontrar determinadas columnas o medidas que tienen nombres de objeto distintos de cómo se las conoce coloquialmente entre usuarios u otros desarrolladores.
- Detectar patrones problemáticos en expresiones DAX o Power Query (M).
- Encontrar propiedades atípicas, como columnas con AvailableInMDX establecido en False, o tablas con IsPrivate establecido en True, o tablas con la actualización deshabilitada o con particiones personalizadas configuradas. También puedes pedirle al LLM que te ayude a escribir reglas personalizadas del Best Practice Analyzer (BPA) para detectar esto automáticamente con Tabular Editor u otras herramientas.
- Realizar operaciones masivas: Cuando tienes que aplicar un cambio en varias partes de tu modelo, el agente puede ayudarte ejecutando código o generando C# Scripts y macros (con Tabular Editor) o notebooks de Python (con Semantic Link Labs), que puedes revisar antes de ejecutarlos para obtener un resultado determinista y repetible. Algunos ejemplos:
- Crear medidas de forma masiva, como inteligencia temporal o agregaciones comunes. Por ejemplo, refactorizar medidas existentes para usar la nueva inteligencia temporal mejorada con calendarios personalizados.
- Establecer propiedades, como cadenas de formato (dinámicas), SummarizeBy, DataType o SortBy.
- Modificar o dar formato a expresiones DAX y Power Query (M). Un ejemplo explícito sería parametrizar la cadena de conexión de una partición de importación en Power Query.
- Ahorrar tiempo en tareas monótonas o repetitivas que no se pueden automatizar fácilmente con scripts: El agente puede encargarse de ciertas tareas que no se pueden automatizar con scripts fácilmente. Normalmente, esto implica que el agente modifique metadatos y, después, tú revises el resultado manualmente. Algunos ejemplos incluyen:
- Redactar descripciones de medidas, columnas y tablas a partir de ejemplos y plantillas (y luego revisarlas tú).
- Sugerir, crear y actualizar traducciones y perspectivas.
- Refactorizar nombres de tablas, columnas, medidas y funciones para seguir una convención de nomenclatura estandarizada.
- Organizar y auditar tu modelo: Relacionado con el punto anterior: si le das a un agente buenas instrucciones y prompts, puede ayudarte a mejorar tu modelo semántico o los procesos a su alrededor. Algunos ejemplos:
- Buscar y corregir antipatrones conocidos que inflan el tamaño del modelo o empeoran el rendimiento de las consultas.
- Refactorizar expresiones DAX para usar una función definida recientemente.
- Separar un “Report grueso” (Report y modelo semántico) en archivos independientes de Power BI Desktop o de proyecto (un “Report ligero” y un modelo).
- Dividir un modelo grande en varios más pequeños, o al revés.
ADVERTENCIA
Si simplemente le dices a un agente “optimiza mi modelo” u “organiza mi modelo”, no esperes obtener buenos resultados. La optimización y la organización varían según el contexto: dependen del modelo y del desarrollador. Estos son buenos ejemplos de casos en los que conviene invertir tiempo en un prompt reutilizable, donde defines contexto y pasos que le indiquen al agente qué significa optimizar y organizar para ti en esta situación.
Aun así, debes esperar cierta iteración antes de conseguir un buen primer resultado.
Diferentes formas en las que un agente puede modificar modelos semánticos
Lo que el agente puede hacer, cómo lo hace y cuán efectivo es depende de varios factores:
- El modelo de lenguaje grande subyacente
- El contexto o las instrucciones que le proporcionas, o que puede recuperar por sí mismo
- Tu prompt o tus instrucciones para iniciar una sesión
- Las herramientas que el agente tiene disponibles, cómo las descubre y cómo están diseñadas
- El entorno en el que opera el agente.
Aunque es interesante examinar cada uno de estos elementos, en esta serie nos centramos en las herramientas. En este contexto, hay varios enfoques para usar la IA y facilitar el desarrollo de modelos. Primero, hay dos enfoques habituales para usar la IA con modelos semánticos que no dependen en absoluto de agentes de programación:

- Copilot en Power BI Desktop incluye varias funcionalidades que pueden facilitar el desarrollo de modelos. En concreto, Copilot puede generar descripciones de medidas individuales, sinónimos en el modelo lingüístico y consultas DAX en la vista de consultas DAX.
- C# Scripts individuales en Tabular Editor y notebooks de Python en Fabric (Semantic Link Labs) pueden permitirte llamar a las API de LLM cuando ejecutas el código; puedes indicarle que genere valores de propiedades (como expresiones o descripciones) y más.
Estos enfoques funcionan, pero son bastante menos potentes que un agente de programación. Los agentes de programación como Claude Code o GitHub Copilot pueden trabajar con un modelo semántico de las siguientes maneras:

NOTA
Este es un resumen de alto nivel. En artículos posteriores, trataremos en detalle cada enfoque, incluidos los pros, los contras y algunos consejos o recomendaciones basados en nuestra experiencia. Como la seguridad es una preocupación tan fundamental, también hemos escrito un artículo aparte que lo trata en detalle.
- Agentes de programación sobre metadatos del modelo en archivos TMDL: El agente de programación puede usar herramientas integradas como Read o Write para ver y modificar directamente los metadatos del modelo. Con este enfoque, guardas el modelo como un Proyecto de Power BI o su definición de forma local y dejas que el agente trabaje sobre los archivos. Esto funciona con los formatos model.bim (TMSL), TMDL y save-to-folder de Tabular Editor (Database.json). Es un enfoque sencillo que no requiere herramientas adicionales, pero es más propenso a errores que pueden provocar metadatos no válidos y puede ser menos eficiente que otros métodos para realizar cambios, especialmente en modelos más grandes o más complejos.
- Agentes de programación con servidores de Model Context Protocol (MCP): Los servidores MCP pueden exponer herramientas que permiten a un agente de programación interactuar de forma programática con el Tabular Object Model (TOM). Con este enfoque, configuras tu agente de programación para usar un servidor MCP que hayas creado tú u otra persona. El agente de programación puede descubrir y usar estas herramientas de forma natural, lo que puede facilitar cambios en los metadatos del modelo, en un modelo abierto en Power BI Desktop o en un modelo publicado en el servicio. Este enfoque puede ser más eficiente y robusto que la manipulación directa de metadatos, ya que las herramientas pueden validar, habilitar operaciones masivas y guiar al LLM. Sin embargo, los servidores MCP consumen muchos tokens en la ventana de contexto, lo que puede degradar el rendimiento del agente y hacer que alcances los límites de uso más rápido. También pueden ser poco flexibles, ya que el agente solo puede usar las herramientas tal y como han sido diseñadas, y no puede modificarlas.
- Agentes de programación que usan herramientas de línea de comandos o API: Los mejores agentes de programación tienen una herramienta Bash que les permite ejecutar comandos en la línea de comandos. Esto significa que los agentes de programación pueden usar herramientas con interfaz de línea de comandos, como Tabular Editor o Fabric CLI, entre otras. Los agentes también pueden usar API o sus wrappers directamente. Con este enfoque, instalas una herramienta de CLI e instruyes al agente para que la use y modifique el modelo utilizando, por ejemplo: scripts de C#. Este enfoque funciona con archivos de metadatos locales, Power BI Desktop y modelos publicados en el servicio de Power BI. Ofrece al agente la máxima flexibilidad, al tiempo que aplica validaciones y evita contaminar la ventana de contexto. Sin embargo, las herramientas de CLI deben estar bien diseñadas para su uso con agentes, y los agentes necesitan buen contexto para herramientas de CLI más nuevas que podrían tener poca presencia en los datos de entrenamiento.
Como puedes ver, cada uno de estos enfoques tiene pros y contras; ninguno es objetivamente mejor que otro. De hecho, es probable que, si estás haciendo desarrollo agéntico de modelos semánticos, uses una combinación de los tres para obtener los beneficios de cada uno.
Y, para reiterarlo, ninguno de estos enfoques es un sustituto de las herramientas tradicionales de desarrollo como Power BI Desktop, Tabular Editor u otras. Más bien, amplían tu flujo de trabajo con posibilidades nuevas e interesantes que pueden ahorrarte tiempo y facilitar el desarrollo guiado por especificaciones.
En conclusión
La IA puede consultar, resumir y modificar modelos semánticos cuando le das las herramientas adecuadas. Estos agentes para modelos semánticos pueden ser útiles para tareas concretas; pueden complementar, pero no sustituir, las herramientas o los flujos de trabajo tradicionales de desarrollo. Hay tres enfoques principales para que un agente trabaje con un modelo semántico: trabajar sobre archivos de metadatos, usar servidores MCP o usar código y herramientas de línea de comandos.
Los siguientes artículos de esta serie analizan cada uno de estos enfoques en detalle, empezando por la modificación directa de los metadatos del modelo. Continúa con la primera parte sobre TMDL aquí.