
Key takeaways
- Part of a series: This article builds on part one.
- Agents can edit TMDL directly: With this approach, an agent reads and writes local (or remote) model metadata files.
- It's simple and source-control friendly: It's easy to start, efficient to search and summarize, and you get checkpoints and version control to revert changes.
- But metadata is fragile: Without good prompts, agents can make breaking changes, and you must deploy or open the model before you can query it.
- Combine approaches and validate: Pair this with MCP servers or code, and validate changes in Tabular Editor or via automated deployment.
This summary is produced by the author, and not by AI.
Using agents to modify model metadata
This series teaches you about the different approaches to use AI to facilitate changes to a semantic model using agents. A semantic model agent has tools that let it read, query, and write changes to a semantic model. Using agents this way is called agentic development, and it can be a useful way to augment traditional development tools and workflows in certain scenarios.
There are several different ways that AI can make changes to a semantic model, including modifying metadata files, using MCP servers, or writing code. Each approach has pros and cons, and if you’ll use AI to make changes to semantic models, then it’s likely that you’ll use all three.
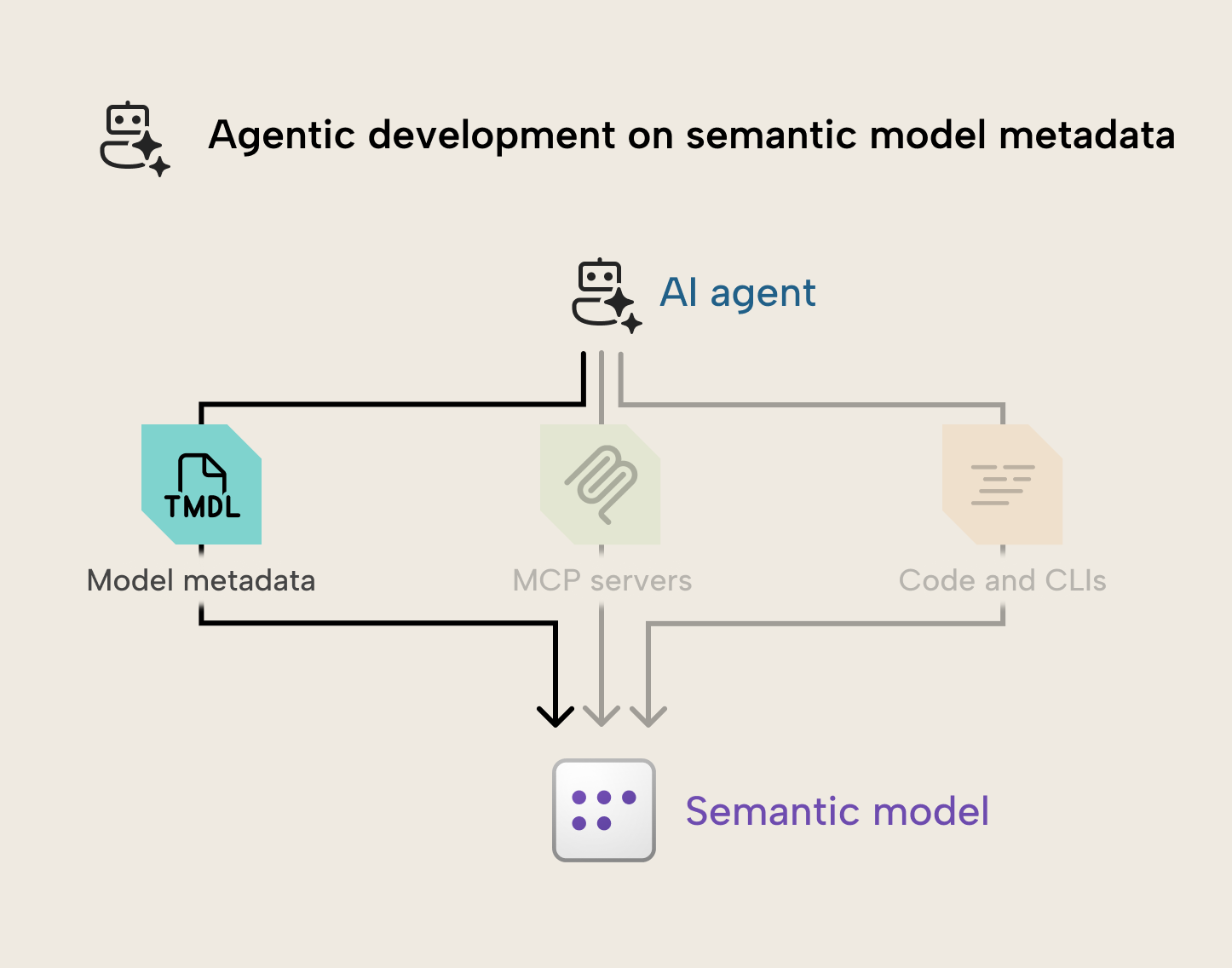
In this article, we examine how you can use a coding agent to read and write changes to model metadata files, directly, including the pros and cons for this approach, and tips to do this successfully based on our experience with this technique, so far.
TIP
This article focuses on direct modification of metadata by a coding agent with its built-in tools. As you’ll see later in this series, we currently recommend that you use either the Power BI modelling MCP server or the Tabular Editor CLI together with the TMDL model metadata. This provides coding agents an efficient way to programmatically model metadata while still being able to directly access it. It also ensures you can more easily view and track changes with source control.
What is model metadata?
When you create and save a semantic model, all the structures, calculations, and properties are saved in the metadata of your Power BI Desktop or Power BI Project (PBIP) file. This is also known as the semantic model definition. If you save your model in the PBIP format, you can open and view this metadata in a text or code editor. We recommend that you use VS Code or Cursor.
This image from the Microsoft Documentation explains the differences between the PBIX and PBIP format, if you’re unfamiliar:
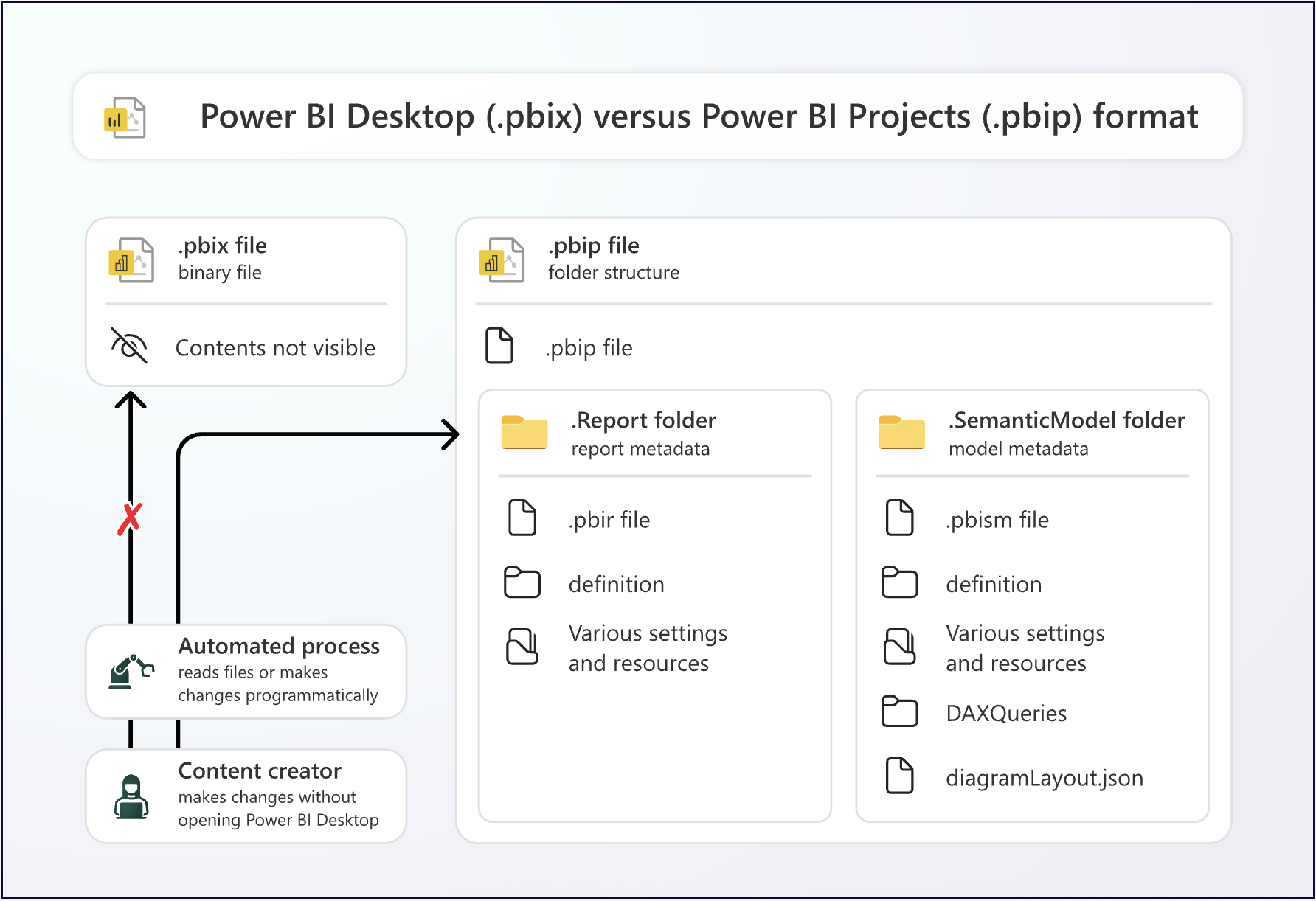
The model metadata is located in the .SemanticModel folder; specifically, the “definition” folder. There are many benefits to being familiar with this metadata, including automation, better tracking of changes with source control and Git integration. The following is an example of what semantic model metadata looks like, if you’ve saved it using the new Tabular Model Definition Language (TMDL) format:
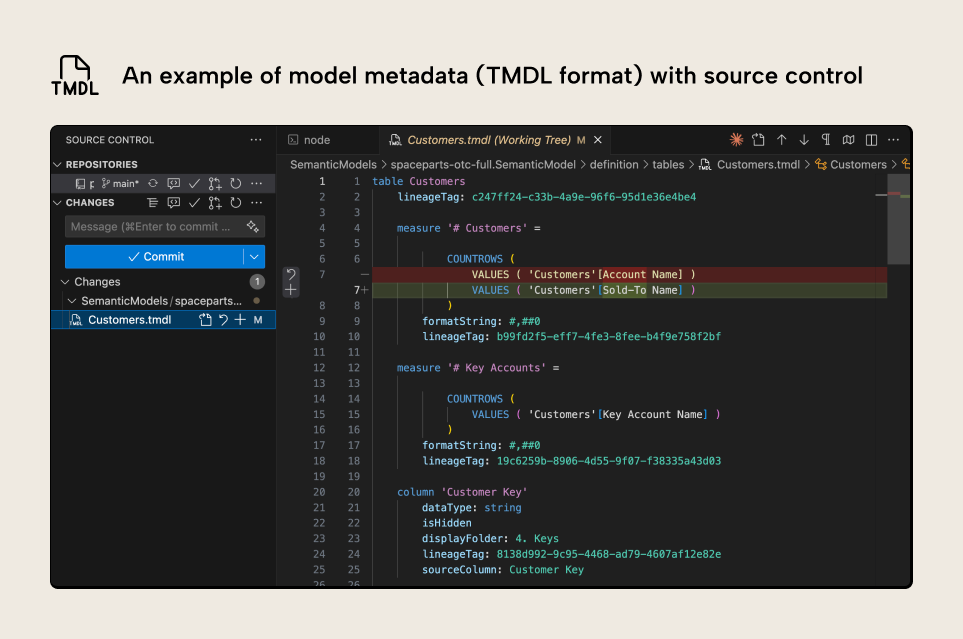
The image shows the metadata for a semantic model table Customers, including metadata for measures and columns in that table. The syntax highlighting is provided by the TMDL extension, which works in VS Code and Cursor. There’s been a change to the # Customers measure. In red, you can see the previous expression, and in green is the new expression.
This example shows how you have visibility to even small changes, but you can also modify model metadata directly, which will result in functional changes to your model. Doing this by hand is tedious and prone to errors. However, it becomes much more interesting when you have a coding agent make changes to the model metadata for you.
To start, here’s a quick demonstration of this approach in action:
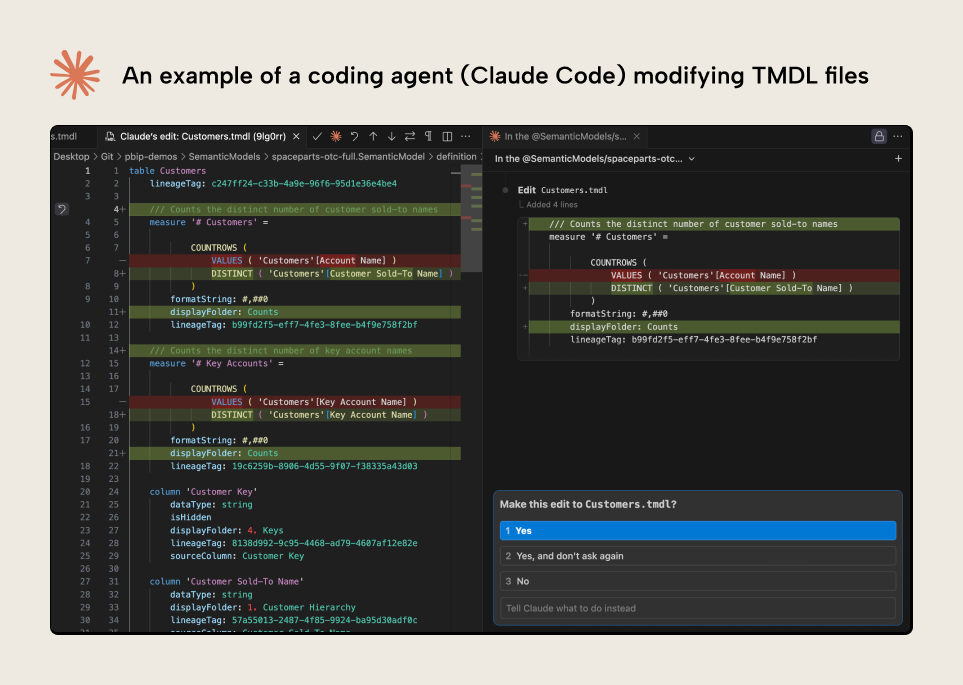
The demonstration shows a coding agent (Claude Code) reading and modifying the semantic model metadata from within VS Code. The agent asks for permission to make the modifications, with removals shown in red and additions in green. This is a simple demonstration; the rest of this article explains how this works and when it might be useful.
How it works: The scenario diagram
This approach involves the agent using read and write tools to directly change the semantic model metadata files. The following diagram depicts a simple overview how you might use an agent to make changes directly to model metadata:

You can understand this process as follows:
- The user saves a Power BI Desktop (.pbix) file as a Power BI Project (PBIP), or saves the semantic model definition as a model.bim, database.json, or TMDL format. This lets you view and modify semantic model metadata.
- The user views the semantic model metadata in a code editor like VS Code or Cursor. This is an optional but recommended step so that you can use the editor to view and manage the files as well as their changes via source control to a remote repository.
- The user curates a base set of instructions (such as
AGENTS.mdorCLAUDE.md) and context (other.mdfiles) about the TMDL format and the semantic model that they want to change. They optionally also configure other agentic tools and components, depending on the coding agent that they use, like the Microsoft Docs remote MCP server or a Claude Code skill. Setting up these instructions and context isn't a one-off activity and requires active curation and maintenance; it’s more of a communication and writing skill than a technical skill. - The user creates a prompt or drafts a plan with the coding agent. This is best done as an iterative exercise with the coding agent before it makes any changes. Context, instructions, and prompts aren’t generated by AI or created by agents, as this may lead to degraded performance.
- The user submits the prompt to start a session.
- The agent ingests its instructions into the context window, which is the finite budget of tokens it can have in an active session. Using tools, it reads other context files and the semantic model metadata, depending on the prompt. The agent might use other tools to retrieve additional information from other files, the web, or your Fabric environment.
- Eventually, the agent uses a write tool to make direct changes to the model metadata. Depending on the model and the agent, these changes happen at a different pace. Some agents can make many changes in parallel, and some models have higher throughput than others.
- The user oversees agent changes. Depending on the agent and the code editor they’re using, they have different visibility and features to support this.
- Eventually, the agent stops making changes. The user can validate these changes in the code editor with the support of the TMDL extension. They can also use Tabular Editor to load the model metadata to see the changes in a semantic model integrated development environment. Some changes may result in invalid metadata files, which must be adjusted, or you have to revert to a previous version of the code via a checkpoint (which is a feature of the agent) or commit (presuming that you are using source control).
- If the user is using Tabular Editor 3, they can use workspace mode to sync any local changes to a published semantic model, which they can process and query to validate those changes. Alternatively, they can set up the coding agent so that it automatically deploys the model to a sandbox workspace, processes it, and queries it via the agent.
NOTE
The diagram focuses on a local, supervised scenario where a single agent operates under human orchestration. You can also operate multiple agents in parallel.
Additionally, you can delegate unsupervised agents in the background like GitHub Copilot, Claude Code on the web or Google Jules, who work on a separate branch of your repository in a container. We may discuss these unsupervised scenarios in a separate article at a later date.
Demonstrations: what this looks like
To make this more concrete, here are a few different examples of agents working with semantic model metadata:
Agentic development with GitHub Copilot
GitHub Copilot is a coding agent that you can use from the user interface of VS Code. You can use GitHub Copilot in agent mode to make specific changes to files. For instance, here, you can add descriptions to tables and measures, based on a template or set of examples.
In the video, you see GitHub Copilot add descriptions to measures and columns in a table (Budget.tmdl) based on an example and prompt. This is a common scenario that many have explored already in a wide range of approaches.
Agentic development with Claude Code
Claude Code works similar to GitHub Copilot. It also has a user interface via the Claude Code extension. The following is an example of Claude Code searching the model for possible reasons to explain why there are (Blank) values in a Power BI report:
As you can see, Claude Code can explore the model metadata based on the prompt and instructions, which explain what referential integrity is, why it happens, and how to validate it. It finds the problem: a filter in the partition of the Products table that excludes products of a certain type. Note that it makes several suboptimal suggestions (like proposing an incorrect filter of the fact table) before removing the filter from Products.
More commonly, however, Claude Code lives in the terminal. You can open a terminal either in the code editor or a separate window, and interact with the coding agent like you would a normal chatbot. Here you can see Claude Code adding a function to the model, then refactoring measures to use that function:
In the demonstration, you can also see the user validate the changes both in the TMDL files and in Tabular Editor 3. Using Tabular Editor 3, the user can use code assistance to identify any DAX syntax issues, and also query the model to validate that the changes produce the expected results.
The rest of this article explains how you set this up for yourself, the pros and cons, and some tips for success.
How to get started
This approach is the easiest to set up and use, since it requires no extra software aside from the code editor and agent. However, most coding agents do require separate licenses. If this is an approach that you want to explore, then you need the following:
- Save your Power BI Desktop (.pbix) file using the Power BI Projects (PBIP) format. The PBIP format saves your model and report into separate project folders, which contain all metadata files that you can read and write. Without the PBIP format, it’s not supported to make changes to model metadata, and you can’t track changes to individual model objects. Alternatively, you can save your semantic model definition using the model.bim (TMSL), database.json (Tabular Editor’s “Save to Folder”), or TMDL formats. We recommend the TMDL format for agentic development moving forward, but model.bim and database.json work well, too, for now.
- A coding agent that you can use like GitHub Copilot in agent mode, Claude Code, or Gemini CLI. Most coding agents require a paid subscription for their use. We recommend Claude Code, which we feel has the best features and developer experience for agentic development in Microsoft Fabric, Power BI, and just overall.
- A remote repository where you can set up source control for your semantic model. Source control is essential for agentic development to mitigate the effects of destructive operations so you can track and manage changes to your work (and revert those changes, if necessary). Most coding agents support “checkpoints” for this, but you should use that secondarily in addition to source control.
- An integrated development environment where you can easily load and browse your model (like Tabular Editor 3) and a text editor where you can manipulate them (like VS Code).
NOTE
You do not need Microsoft Fabric, Premium-Per-User, or even Power BI Pro for this approach, since you’re modifying local metadata files.
How this approach differs from others
This approach is somewhat distinct from the other three, since the agent is reading and modifying metadata, directly. When an agent uses an MCP server or CLI, it's doing so indirectly via code. There's a few key benefits and challenges that arise because of this.
Benefits of this approach
There are a few unique benefits of this approach:
- Search: The biggest benefit of this approach is that it’s the quickest and most efficient way for AI to search or summarize a semantic model. Whether the coding agent is using a Read tool, a Bash tool, or a more complex semantic search, it can much more quickly check the local files for a particular word or pattern, while keeping token consumption to a minimum.
- Easier to “undo” changes: When you make changes to model metadata files, it’s easier to revert changes to a previous checkpoint or commit. When you make changes to a local model open in Power BI Desktop or a published model in the service, this is much harder. This is actually a huge benefit, because if you “break” your model or perform a destructive operation, you might be in trouble if you’re working directly on a local or remote semantic model rather than its metadata.
- Simplicity: Since you’re basically just modifying text files, it’s easy to understand what the agent is doing and what changes it made. You also don’t need to install anything, and improving agent performance just means improving your context files and prompts.
- Security: Since you’re not reliant on the agent executing arbitrary code or using MCP server tools, there is less risk with this approach. It might be simpler to make it more secure or private, since you can confine the agent to a container or even use a local LLM without relying on the model’s code generation or tool-calling performance.
- Modularity: You can combine this approach with others. For instance, agents can use MCP servers and code to manipulate model metadata, rather than writing to it, directly. There might be cases where it’s quicker or easier to modify the file (such as single changes) and cases where it isn’t, so the agent can use an MCP server or code.
Despite its simplicity, this approach generally also has the most caveats and limitations.
Challenges with this approach
There are several challenges for agentic development, here:
- Difficulty validating changes: The biggest caveat with modifying local files is you can’t query them or test how changes alter the data or calculations. To do that, you have to first open the model in Power BI Desktop or deploy it to a workspace, and process it. You can streamline or even automate this (such as using Tabular Editor 3 in workspace mode or by using the Fabric CLI). Furthermore, if changes result in invalid TMDL, that is difficult to validate with the files alone (even with the TMDL extension). Other approaches restrict the possible operations, limiting this from happening.
- Fragility: Since the agent is just modifying text files directly, it can easily make mistakes which result in invalid TMDL. For instance, TMDL is whitespace-sensitive; indentation and seemingly innocuous syntax changes can lead to invalid files.
- Complexity: TMDL is unique because it contains three or more different syntax types. A TMDL file can contain semantic model metadata, as well as DAX expressions, Power Query (M) expressions, and rarely other syntax (such as SQL for native queries, or Python and R with Power Query integration). These embedded syntax types can easily confuse the agent, resulting in TMDL syntax appearing in a large DAX expression, or vice-versa.
- New metadata formats: TMDL and PBIR are new formats that are sparse in LLM training data. You might even find that models can better generate or manage TMSL and legacy report metadata than TMDL and PBIR. As such, you have to put more effort into creating and curating context to work with these formats, properly.
- Inefficient or slow: With this approach, you’re waiting on the agent to find the object or property you want to change and then generate the correct value to change it. On top of that, you need to validate it in a program that “builds” the model from the metadata. For many simple changes and most additions, this will just take much longer (and cost much more) than making the changes yourself. This becomes useful when patterns are consistent, but the values are not (like descriptions, display folders, or expressions). This is especially true for larger, more complex semantic models.
- Poor at generating new files and properties: Generating entire new .tmdl files is a lengthy process where there’s a high likelihood of the LLM making a mistake.
- Context rot: If the agent must read the model metadata before making changes each time, it can consume a lot of tokens, filling up the context window. This can lead to reduced performance and higher cost, or more quickly hitting session limits. This is especially true with tables that have many measures and columns, since all of this is defined in the specific table’s .tmdl file.
Despite these challenges, there are still some cases where this might be your preferred approach.
When you might use this approach
There are a few cases when you might use this approach over others:
- Searching or exploring a model, particularly if it’s a model that you didn’t make. This should be done in parallel with exploring it in another tool like Tabular Editor or Power BI Desktop, where you can better see the distinct objects and how they relate to one another, such as in a model diagram. Examples could be searching for a particular code pattern, column, or property, especially if you can describe it roughly without knowing the exact name or value.
- Simple or single adjustments that aren’t easy to do with a user interface or scripting. Examples include refactoring existing simple property values (like display folder names) or removing part of a DAX or Power Query expression (like a filter) present in multiple instances.
- Adjusting object names or property values in bulk that are already set. Examples could be renaming or refactoring objects. Note that when you need to modify multiline properties, even simple changes can become problematic, due to TMDL being whitespace and tab-sensitive.
When you might not use this approach
There are also a few cases when this approach isn’t preferable, and you should instead use either MCP servers, programmatic interfaces, or traditional development:
- Changes with dependencies. Many changes you might make to model metadata can have effects on downstream objects. Simple examples include renaming tables, columns, or measures, which might not be renamed in expressions that reference them. You can also run into issues if you modify properties that require a higher model compatibility level, or that interact with lesser-documented properties and annotations.
- Adding new properties and objects. When you have to add new tables, measures, and columns to your model, there’s a higher chance that the agent makes a mistake with the TMDL syntax or indentation.
- Changes that require validation. Changes to DAX and Power Query expressions can be problematic with model metadata, because you don’t get any feedback about whether the syntax is correct.
These are just a few examples. In summary, working with metadata files is typically faster and more efficient with read and summarization operations, or simple changes to existing objects and properties. For most other cases, you want to instead use alternative approaches.
Tips for success with agents on TMDL files
Despite its simplicity, there’s still a lot of things to keep in mind with this approach. It’s very easy to end up with bad results or waste a lot of time, especially if you don’t invest in good context or use slow models.
- Use checkpoints and source control: It’s extremely important that you can quickly and easily revert changes when you’re conducting agentic development. This is a key advantage of this approach; don’t squander it and risk breaking or losing important work.
- Use faster models with higher throughput: Models like Composer from Cursor or Haiku 4.5 from Anthropic work best for this approach. These models have a very high throughput and still decent accuracy and ability to follow instructions. This helps offset the inefficiency from waiting for the model to make file changes.
- Context is everything: You can’t have consistent success with this approach unless you invest in creating good instructions and prompts. This is an up-front investment that can take time, but it can be worthwhile.
- Use the Microsoft Docs MCP server or
WebSearch/Fetchtools: You can instruct the agent to retrieve information about the metadata formats and even about semantic models in general. This is a useful tip irrespective of what approach you take, but it’s particularly helpful if agents will work on metadata, directly. - Use the TMDL extension in VS Code: The Visual Studio Marketplace extension provides syntax highlighting and some validation to make it easier to work with TMDL. Some coding agents that integrate with your IDE can also leverage the extension to see this validation and improve its outputs.
- Validate with each session: After performing modifications with a coding agent, you shouldn’t just read the TMDL files. You should open the model in a functional tool to actually view the changes and identify any errors or warnings. For instance, if you open your model in Tabular Editor, semantic analysis warnings and errors will alert you to problems, while you can also use the Best Practice Analyzer and other tools to find issues to address.
- Consider how to integrate with CI/CD: One of the biggest shortcomings of this approach is that you can’t query the model after or while making changes for validation. One way to deal with this is to set up processes to automatically deploy (and reprocess) the model at the end of a session to a sandbox workspace. Then, you can use other tools like MCP servers or the Fabric CLI to query the model.
- Don’t use this approach alone; combine it with others: For best results, you should combine this approach with MCP servers or code/APIs/CLI tools. That way, you can leverage programmatic approaches for more efficient bulk operations, while still benefiting from quick model search and summaries, or single-file modifications.
- Keep your model metadata open in Tabular Editor: Tabular Editor can reload your model metadata after each change, and can help you validate changes. With Tabular Editor 3, you benefit from semantic analysis and DAX code assistance, as well as automatic scanning for best practice violations, and DAX Optimizer to find bottlenecks. With workspace mode, you can also ensure your model is up-to-date in a workspace for querying. If you prefer not to use Tabular Editor, then we reiterate that you should set up some kind of automated deployment with the Fabric CLI to a workspace.
- Use an agent that lives in the terminal: You might experience better and faster results with command-line agents like Claude Code or the GitHub Copilot CLI over agents that have a user interface. This is just from the author’s subjective experience.
These are just a few things to keep in mind. We’ll keep this article up to date as this area evolves; you can bookmark it and come back, regularly.
For further reading
- Agentic development of semantic models in simple terms (Tabular Editor Blog). The introductory article compares the TMDL file, MCP server, and CLI approaches so the narrower guidance here has context.
- Visual Studio Code and extensions for Power BI developers in simple terms (Tabular Editor Blog). Covers the editor environment where agents typically operate on TMDL files, including extensions that add syntax highlighting and diff views.
- TMDL overview (Microsoft Learn). Microsoft's official specification for TMDL, covering file structure, object syntax, and serialization rules that agents must respect.
- Power BI Projects (Microsoft Learn). Describes the PBIP project structure that exposes semantic model and report metadata as files.
In conclusion
One approach for agentic development is modifying model metadata files, directly. This approach is the simplest to set up and use, but it also has the most caveats, including a high dependency on good context and prompts, difficulty validating results, and specific challenges like whitespace with TMDL. However, it is also the fastest and most efficient approach for an agent to search and explore the model, and the most straightforward way to use asynchronous (or background) agents working unsupervised to either review or work on specific features.
The next article in this series discusses a second approach, where you give an agent a model context protocol (MCP) server to manipulate model metadata.
Let agents edit TMDL, then validate changes in Tabular Editor 3.
Give Tabular Editor a spin

