
Key takeaways
- Agents can query or modify models: Some agents only read and query semantic models for conversational BI, while others use tools to change the model metadata.
- Agentic development can help, with care: Applied in the right scenarios with deliberate preparation, agents save time; without it, they can add time, cost, and risk.
- Coding agents are the interesting part: Tools like GitHub Copilot and terminal agents like Claude Code enable far more useful scenarios than Copilot or API calls alone.
- Three ways to modify a model: Coding agents can edit metadata directly, use semantic model MCP servers, or use command-line tools and libraries, often combining all three.
- This series explores the approaches: We examine each approach and its trade-offs, with concepts that apply to reports and software development more broadly.
This summary is produced by the author, and not by AI.
Using AI agents with semantic models
Since the emergence of ChatGPT, there’s been interest to use AI to help write DAX and build semantic models. Previously, this was limited to copy-pasting code from a chatbot, using Copilot in Power BI, or calling APIs from scripts and notebooks. Now, the advent of coding agents like Claude Code from Anthropic make this much more interesting and plausible. Coding agents are AI systems where the large language model (LLM) can generate and execute code using tools in a loop.
In the context of a semantic model, an agent can be defined in one of two ways:
- Agents that query semantic models: Explores metadata and generate queries against the model to retrieve information and answer user data questions. We typically refer to this as conversational BI, as opposed to traditional BI, where users view data in visuals or tables from model queries. An example of a consumption agent could be Copilot’s “ask data questions” experiences, or data agents on semantic models in Microsoft Fabric.
- Agents that modify semantic models: Reads and modifies semantic model metadata, either directly or programmatically, and interacts with the environment around the semantic model. We refer to this as agentic development of semantic models. Such an agent might not only modify properties and generate DAX or Power Query expressions, but also download, deploy, and manage semantic models. Agents that can modify semantic models can typically also query it; for instance, you can query a semantic model with any coding agent (like Claude Code) but querying the model here is typically done to inform or validate specific changes.
In this series of articles, we focus on agents for semantic model development. Specifically, we focus on the current landscape of tools and approaches, discussing the potential use-cases, benefits, and caveats of each.
It’s easier to show what an agent is, rather to explain it. To demonstrate, here’s an example of Claude Code making changes to a semantic model in a contained environment. Specifically, it’s refactoring model measures to use a DAX function, and renaming those measures to follow some standard naming conventions:
In the demonstration, the agent has access to local model metadata, a Power BI MCP server, and the Tabular Editor CLI to execute C# scripts against semantic models. It can search the model to find measures to refactor, read the function it must use to understand its syntax, and then modify the DAX for all measures, which a user can then validate. Refactoring DAX like this is one example of a useful use-case for agentic model development.
NOTE
You do not choose between AI and non-AI approaches for consumption or development of a semantic model. Rather, you use both, choosing the right approach for a particular problem or scenario. Typically (at least right now) you use AI approaches to augment your existing workflows if they can support it.
If you’re looking to understand the different scenarios in which you can leverage AI and agentic development more broadly, the author has written about this on SQLBI in detail. See this article and white paper.
What is agentic development of a semantic model?
This means that an agent has access to tools to view and modify model metadata. It can read the names, expressions, and other properties of tables, columns, DAX measures, and other objects. The agent can create, modify, or even delete them. Typically, the tools that the agent uses to do this let the LLM generate property values, like a display folder name, or a measure description.
The following diagram depicts in simple terms how this process looks:
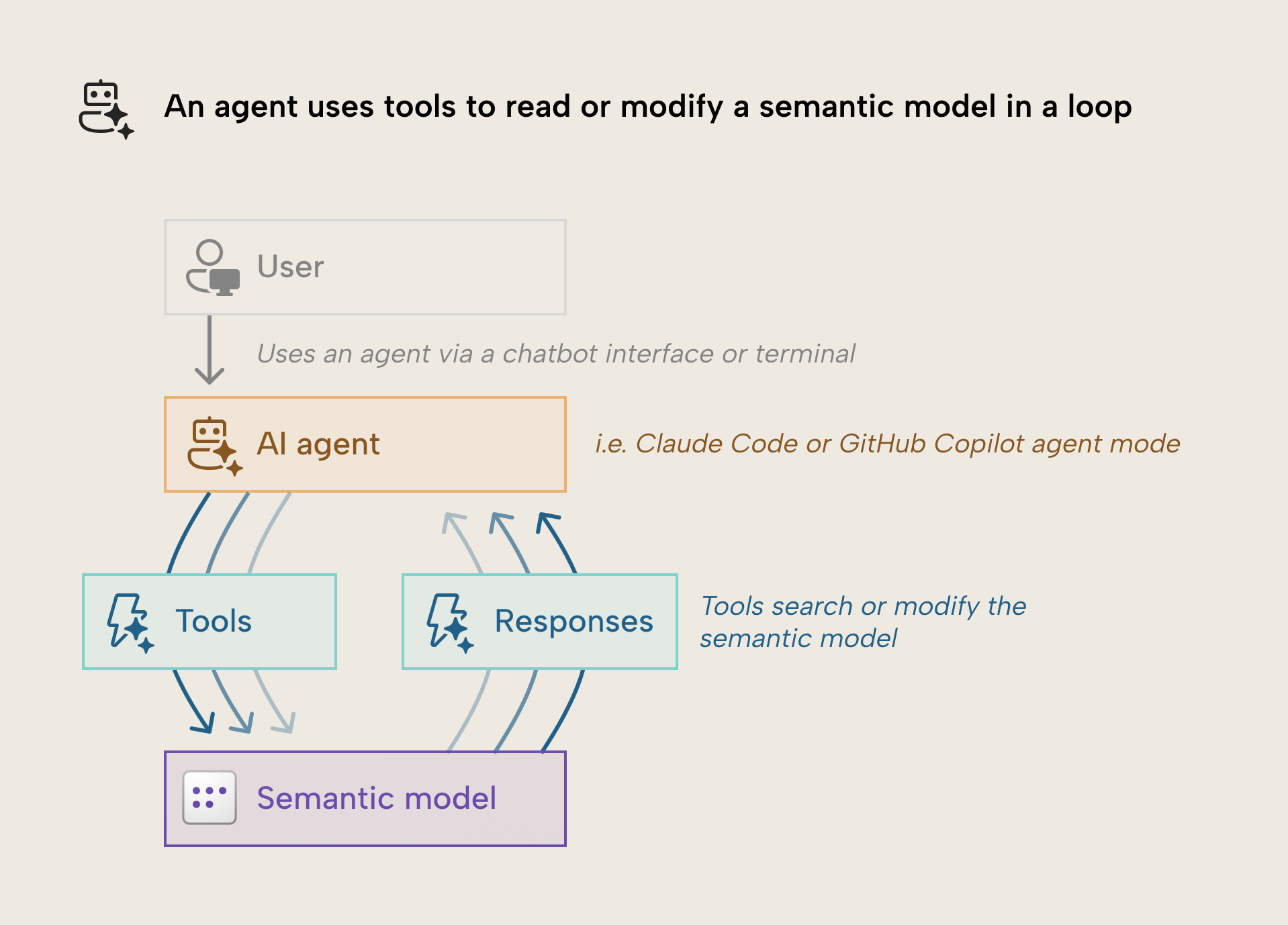
The process is as follows:
- A user provides a prompt, instructing the agent to do something with the semantic model, typically via a chatbot interface.
- The agent ingests some kind of context, such as other files, conversation history, and its system prompt. Most commonly, this takes the form of markdown files on your computer that you write and the agent reads at the start of or during a session.
- The agent uses its tools in a loop to interact with the semantic model and reads the tool responses. The agent can make multiple tool calls at once or (depending on the system) in parallel.
- Eventually, the agent exits the tool-calling loop, and provides an output back to the user, who can validate the result in a client tool like Tabular Editor, Power BI Desktop, or VS Code.
We’ll discuss how the agent can do this, but let’s first examine why agentic development might be useful.
Why and when would you perform agentic development?
Theoretically, you can use an agent to develop and manage an entire semantic model, end-to-end. This has already been the case since the advent of coding agents early this year, as we discussed and demonstrated in an earlier article. Indeed, the novelty of using natural language to take actions in an environment is certainly both impressive and exciting!
However, agentic development is more useful and efficient (both in terms of cost and time) when you apply it to specific scenarios. Here are several reasons for this:
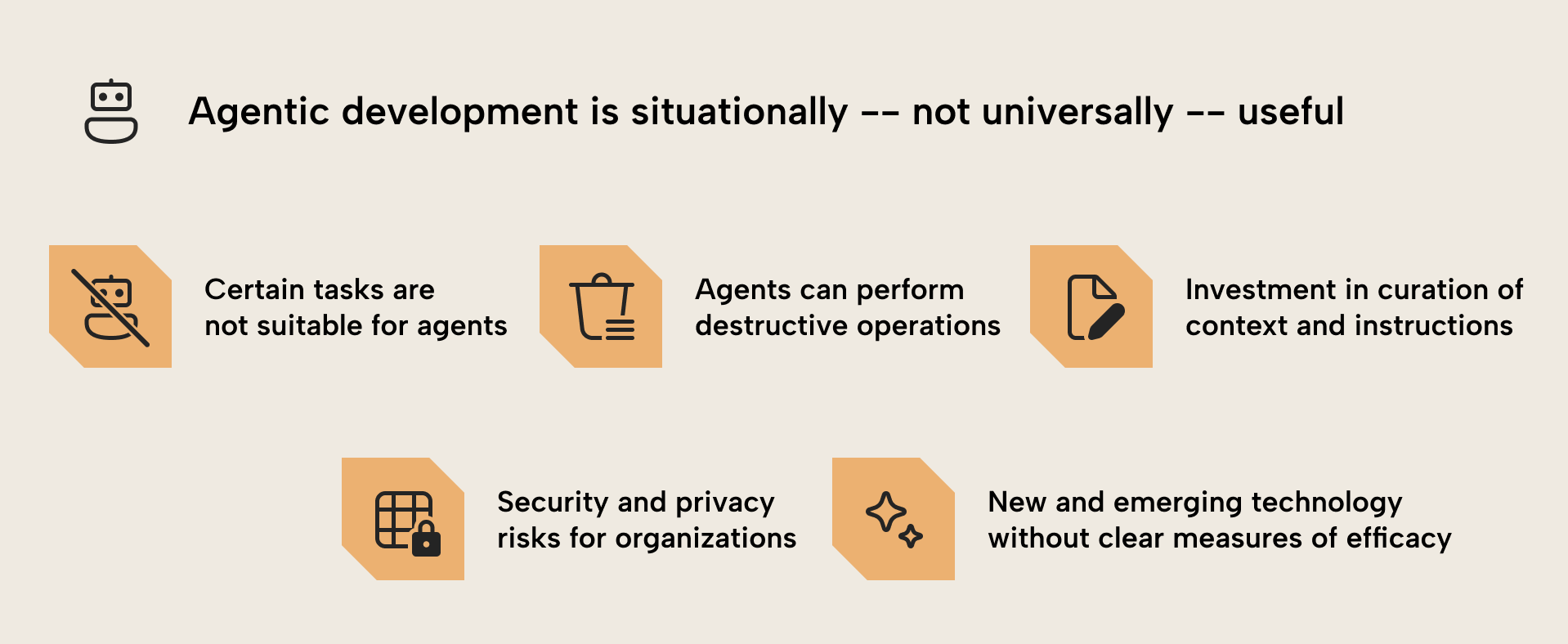
- Agents are better at some tasks than others. For instance, agents can be quite good at refactoring code, but less good at generating code or metadata that is whitespace sensitive, e.g. TMDL documents.
- Agents can perform destructive operations. Changing, moving, or removing even one measure in a semantic model can lead to broken reports, upset users, and wasted time. When using agents, you need to make sure that you are diligently managing source control, checkpoints, automated testing, and agent permissions to avoid accidents.
- To perform well, agents require detailed instructions and information about a task. You need to spend significant time to write this context in instruction files for the agent, and there’s no guarantee that this cost will lead to a return on investment, i.e., faster or higher quality development. Getting AI to write this context for you also doesn’t reliably work; it often even leads to worse results.
- Coding agents and LLMs in general carry various data security and privacy risks for organizations. Most free/public agents are bound by terms that might not align with many organizations’ data privacy and security policies. Unless you have an enterprise subscription vetted by your employer and approved for use with your organization’s data, you should restrict your work to data and metadata that aren't sensitive. This is especially true for consultants who seek to use coding agents to facilitate client work on their data or metadata.
- This is nascent (new and emerging) technology. Many are still trying to figure out the best approaches to get agents to work well, reduce cost, and mitigate risks. There are few best practices, and a high rate and volume of change. Worse still, agent performance is very difficult to measure for specific tasks. Benchmarks are largely performative, shallow indicators to compare models alone, and fail to consider other factors (prompt, context, tools, and environment). Many of these tests “lack scientific rigor” and might not be useful or reliable for real-world application.
Note that the previous caveats aren’t necessarily reasons to neglect or reject agentic development, altogether. On the contrary, they’re just important to keep in mind so that you best leverage this technology while mitigating its risks. There are many ways that agentic development can be beneficial. Here are a few examples of use cases where using an LLM with your semantic model can make sense:

NOTE
We aim to highlight use-cases where we think that LLMs can offer improvements to existing, non-AI approaches in addressing certain problems. These improvements can be either due to strengths in the LLM approach or convenience for the user, but only when considered against realistic risks and caveats.
- Helping you search through or summarize parts of a model: When you’re dealing with a model made by someone else, it can be difficult to “navigate the spaghetti”. Using an efficient model like Haiku 4.5 can be a good way to help you to find certain objects, patterns, or issues (rather than another model like Sonnet 4.5, since Haiku 4.5 is known to be faster and more efficient at searching and summarization). Examples of this could include:
- Finding certain columns or measures that have different object names than what they are colloquially referred to by users or other developers.
- Finding problematic patterns in DAX or Power Query (M) expressions.
- Finding atypical properties, like columns that have
AvailableInMDXset toFalse, or tables that haveIsPrivateset toTrue, or tables that have refresh disabled or custom partitions configured. You can also get the LLM to help you write custom best practice analyzer (BPA) rules to find this automatically with Tabular Editor or other tools.
- Performing bulk operations: When you have to apply a change in multiple places of your model, the agent could help you do this by executing code or generating C# scripts and macros (with Tabular Editor) or Python notebooks (with Semantic Link Labs) that you can review before executing to get a deterministic, repeatable result. Examples of this might include:
- Creating measures in bulk, such as time intelligence or common aggregations. For instance, refactoring existing measures to use the new enhanced time intelligence with custom calendars.
- Setting properties, like (dynamic) format strings,
SummarizeBy,DataType, orSortBy. - Modifying or formatting DAX and Power Query (M) expressions. An explicit example could be using an agent to parameterize the connection string of an import partition in Power Query.
- Save time on monotonous or repetitious tasks that aren’t easily scriptable: The agent can conduct certain tasks that can’t be easily scripted. This typically involves the agent modifying metadata before you review the result yourself, manually. Some examples include:
- Drafting measure, column, and table descriptions based on some examples and templates (then reviewing them, yourself)
- Suggesting, creating, and updating translations and perspectives.
- Refactoring table, column, measure, and function names to follow a standardized naming convention.
- Organizing and auditing your model: Related to the previous point, if you provide good instructions and prompts to an agent, it can help you improve your semantic model or the processes around it. Some examples of this include:
- Searching for and addressing well-known anti-patterns that cause inflated model size or poor query performance.
- Refactoring DAX expressions to use a newly-defined function.
- Separating a report and semantic model “thick report” into separate Power BI Desktop or Project files (a “thin report” and a model).
- Separating a large model into multiple smaller ones, or vice-versa.
WARNING
If you just tell an agent “optimize my model” or “organize my model”, don’t expect to get good results. Optimization and organization are contextually different depending on the model and the developer. These are good examples of cases where you want to spend time on a re-usable prompt, where you define some context and steps that tell the agent what optimization and organization means for you in this circumstance.
Even then, you should expect some iteration before you get a good first result.
Different ways that an agent can modify semantic models
What the agent can do, how it does this, and how effective it is depends on several factors:
- Its underlying large language model
- The context or instructions you provide it, or which it can retrieve itself
- Your prompt or instructions to start a session
- The tools that the agent has available, how it discovers them, and how they are designed
- The environment in which the agent is operating.
While it’s interesting to examine each of these different elements, we focus in this series on the tools. In this context, there are several different approaches by which you can use AI to facilitate model development. First, there are two common approaches that don’t rely on coding agents at all:

- Copilot in Power BI Desktop has several features that can facilitate model development. Specifically, Copilot can generate individual measure descriptions, synonyms in the linguistic model, and DAX queries in the DAX query view.
- Individual C# scripts in Tabular Editor and Python notebooks in Fabric (semantic link labs) can let you call the LLM APIs when you execute the code, which you can prompt to generate property values (like expressions or descriptions) and more.
These approaches work, but are far less powerful than a coding agent. Coding agents like Claude Code or GitHub Copilot can work with a semantic model in the following ways:

NOTE
This is a high-level overview. We’ll discuss in separate follow-up articles we’ve written each approach in detail, including pros, cons, and some tips or guidance from our experience. Since security is such a fundamental concern, we’ve also written a separate article that discusses this in detail, as well.
- Coding agents on model metadata: The coding agent can use built-in tools like Read or Write to view and modify model metadata directly. With this approach, you save the model as a Power BI Project or its definition locally and let the agent work on the files. This works with model.bim (TMSL), TMDL, and Tabular Editor’s save-to-folder database.json formats. It’s a simple approach that requires no extra tools, but it’s more susceptible to mistakes that can lead to invalid metadata and can be less efficient than other methods for making changes, especially on larger or more complex models.
- Coding agents with Model Context Protocol (MCP) servers: MCP servers can expose tools that let a coding agent programmatically interact with the Tabular Object Model (TOM). With this approach, you configure your coding agent to use an MCP server that you or someone else built. The coding agent can naturally discover and use these tools, which can facilitate changes to model metadata, a model open in Power BI Desktop, or a model published in the service. This approach can be more efficient and robust than direct manipulation of metadata, since tools can validate, enable bulk operations, and steer the LLM. However, MCP servers use a lot of tokens in the context window, which can lead to decaying agent performance and result in hitting usage limits, faster. They can also be inflexible, since the agent can only use the tools as they’ve been designed, and can’t modify them.
- Coding agents that use command-line tools or APIs: The best coding agents have a Bash tool that allows them to execute commands in the command-line. This means that coding agents can use tools with a command-line interface, like the Tabular Editor or Fabric CLI, and others. Agents can also use APIs or their wrappers directly. With this approach, you install a CLI tool and instruct the agent to use it to modify the model by using i.e. C# scrips. This approach works with local metadata files, Power BI Desktop, and published models in the Power BI service. It gives the agent maximal flexibility, while also enforcing validation, and avoiding polluting the context window. However, the CLI tools need to be well-designed for agentic use, and agents need good context for newer CLI tools that might be sparse in training data.
As you can see, each of these approaches have pros and cons; none is objectively better than the other. In fact, it’s likely that if you are performing agentic semantic model development that you’ll use a combination of all three to get the benefits of each.
To reiterate, none of these approaches are a replacement for traditional development tools like Power BI Desktop, Tabular Editor, or others, either. Rather, they augment your workflow with some new and interesting possibilities that can save you time and facilitate specification-driven development.
For further reading
- What is an AI Agent for Semantic Models? (Tabular Editor Blog). Defines what an AI agent is in semantic model work, including the difference between agents that query a model and agents that modify it.
- AI agents that work with TMDL files (Tabular Editor Blog). Covers the direct metadata-editing approach in more detail, including where TMDL is useful and where it needs additional guardrails.
- Introducing AI and agentic development for business intelligence (SQLBI). Provides broader context for agentic development patterns in Power BI and business intelligence workflows.
- TMDL overview (Microsoft Learn). Microsoft's specification for the Tabular Model Definition Language, the text-based metadata format behind many agent-editable workflows.
In conclusion
AI can query, summarize, and modify semantic models when you give them the right tools. These semantic model agents can be useful for specific tasks; they can augment but not replace traditional development tools or workflows. There are three main approaches for an agent to work with a semantic model: working on metadata files, using MCP servers, or using code and command-line tools.
The following articles in this series look at each of these approaches in detail, starting with direct modification of model metadata. Continue with part one here.
Give semantic model agents the right tools with Tabular Editor 3.
Give Tabular Editor a spin