
Este contenido fue traducido mediante IA y no ha sido revisado por un editor humano. Las imágenes y los gráficos permanecen en su idioma original.
Conclusiones clave
- Este artículo forma parte de una serie. Empieza por la primera parte aquí.
- Los agentes pueden modificar directamente metadatos del modelo, como archivos TMDL. Con este enfoque, el agente trabaja con archivos de metadatos locales para leer y escribir cambios. Los agentes no supervisados también pueden trabajar con archivos de metadatos en un repositorio remoto.
- Este enfoque es sencillo y te permite beneficiarte del control de código fuente. Sus principales ventajas son que es fácil empezar, es eficiente para buscar y resumir, y puedes aprovechar puntos de control y el control de código fuente para revertir cambios.
- Sin embargo, los archivos de metadatos son frágiles y difíciles de validar. Sin buenas instrucciones y prompts, los agentes pueden introducir fácilmente cambios que rompen los metadatos de un modelo semántico. Además, tienes que desplegar los metadatos del modelo o abrirlos en Power BI Desktop antes de poder consultarlos. Leer o escribir metadatos del modelo también puede ser caro y lento.
- Combina este enfoque con otros y define una estrategia de validación. Este enfoque funciona mejor si lo combinas con servidores MCP o con código para aprovechar las ventajas de cada uno. Valida los cambios, ya sea en Tabular Editor (con Code Assist, modo del área de trabajo y otras funciones) o configurando un despliegue automatizado en un Workspace.
Este resumen lo ha elaborado el autor, no la IA.
Uso de agentes para modificar metadatos del modelo
Esta serie te enseña distintos enfoques para usar IA y facilitar cambios en un modelo semántico mediante agentes. Un agente para modelos semánticos tiene herramientas que le permiten leer, consultar y escribir cambios en un modelo semántico. Usar agentes de esta forma se llama desarrollo con agentes, y puede ser una forma útil de complementar herramientas y flujos de trabajo tradicionales en ciertos escenarios.
Hay varias maneras de que la IA haga cambios en un modelo semántico, como modificar archivos de metadatos, usar servidores MCP o escribir código. Cada enfoque tiene pros y contras, y si vas a usar IA para hacer cambios en modelos semánticos, lo más probable es que uses los tres.
En este artículo analizamos cómo puedes usar un agente de codificación para leer y escribir cambios directamente en los archivos de metadatos del modelo, incluidos los pros y los contras de este enfoque, y consejos para hacerlo bien basados en nuestra experiencia con esta técnica hasta ahora.
CONSEJO
Este artículo se centra en la modificación directa de los metadatos por parte de un agente de codificación con sus herramientas integradas. Como verás más adelante en esta serie, actualmente recomendamos que uses powerbi-modelling-mcp o TE2 CLI, junto con los metadatos del modelo en TMDL. Esto ofrece a los agentes de codificación una forma eficiente de trabajar con metadatos del modelo de manera programática, sin perder el acceso directo a ellos. Además, facilita ver y seguir los cambios con el control de código fuente.
¿Qué son los metadatos del modelo?
Cuando creas y guardas un modelo semántico, todas las estructuras, cálculos y propiedades se guardan en los metadatos de tu archivo de Power BI Desktop o de Proyecto de Power BI (PBIP). Esto también se conoce como la definición del modelo semántico. Si guardas tu modelo en formato PBIP, puedes abrir y ver estos metadatos en un editor de texto o de código. Te recomendamos usar VS Code o Cursor.
Esta imagen de la documentación de Microsoft explica las diferencias entre los formatos PBIX y PBIP (Proyecto de Power BI), por si no los conoces:
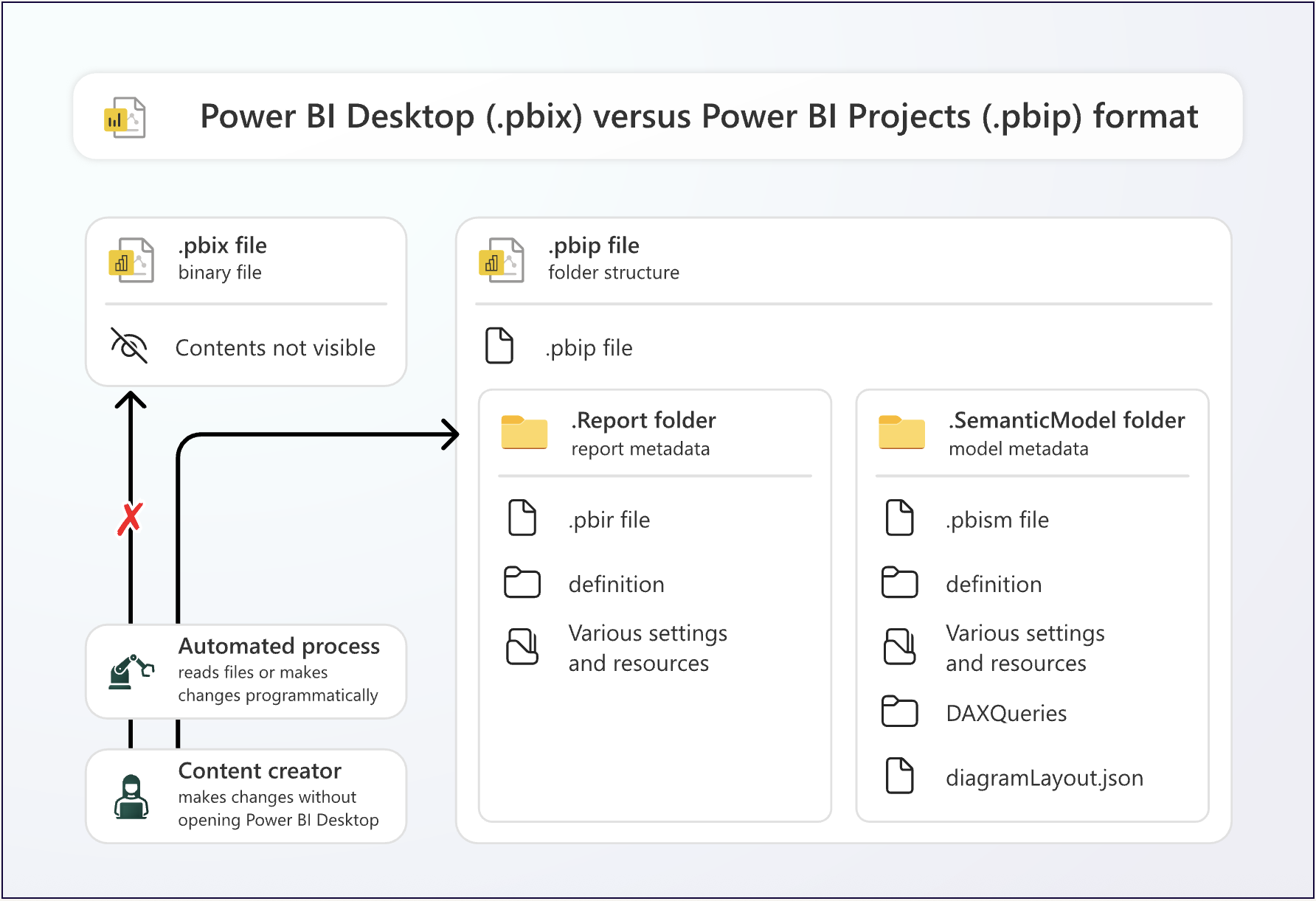
Los metadatos del modelo se encuentran en la carpeta .SemanticModel; en concreto, en la carpeta “definition”. Familiarizarte con estos metadatos aporta muchos beneficios, como la automatización, un mejor seguimiento de los cambios con control de código fuente y la integración con Git. A continuación se muestra un ejemplo de cómo se ven los metadatos de un modelo semántico si los has guardado con el nuevo formato Tabular Model Definition Language (TMDL):
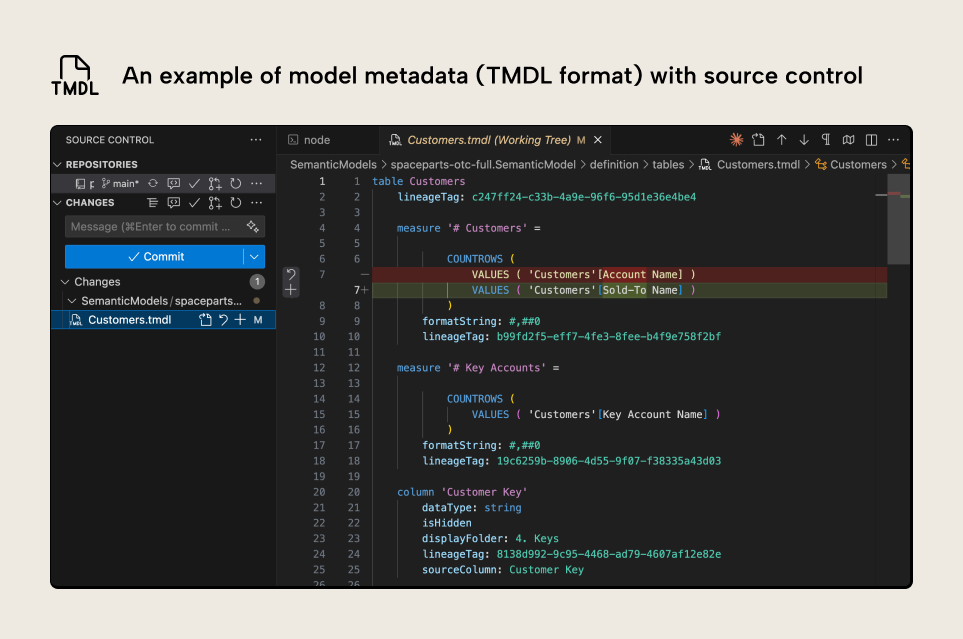
La imagen muestra los metadatos de una tabla de modelo semántico, Customers, incluidos los metadatos de las medidas y columnas de esa tabla. El resaltado de sintaxis lo proporciona la extensión de TMDL, que funciona en VS Code y Cursor. Ha habido un cambio en la medida # Customers. En rojo puedes ver la expresión anterior, y en verde está la nueva.
Este ejemplo muestra que tienes visibilidad incluso sobre cambios pequeños, pero también puedes modificar los metadatos del modelo directamente, lo que se traducirá en cambios funcionales en tu modelo. Hacerlo a mano es tedioso y propenso a errores. Sin embargo, se vuelve mucho más interesante cuando un agente de codificación realiza los cambios en los metadatos del modelo por ti.
Para empezar, aquí tienes una demostración rápida de este enfoque en acción:
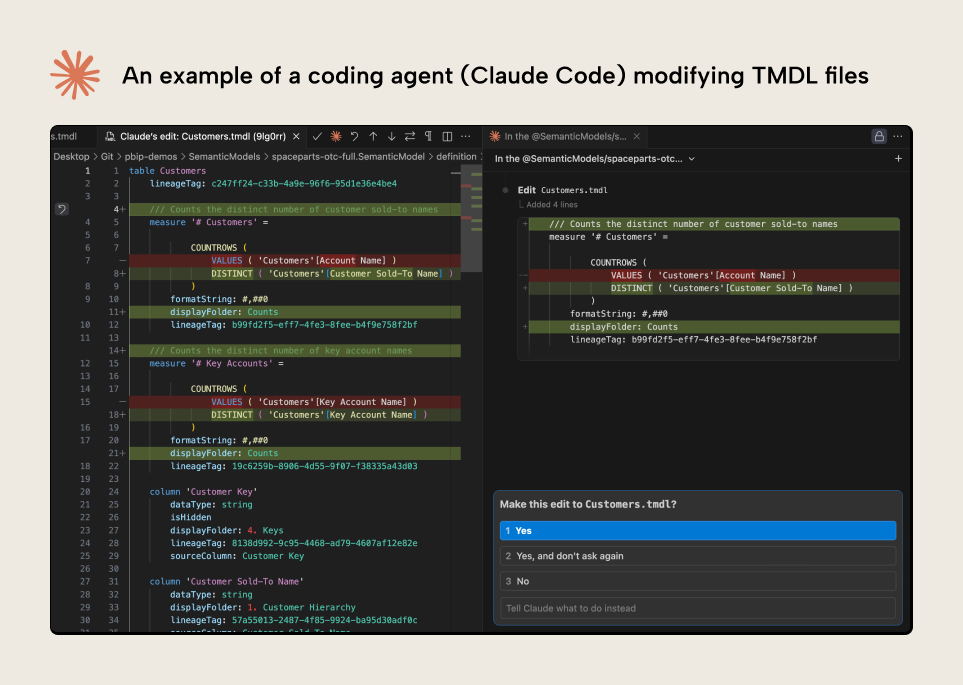
La demostración muestra a un agente de codificación (Claude Code) leyendo y modificando los metadatos de un modelo semántico desde VS Code. El agente pide permiso para aplicar las modificaciones, con las eliminaciones en rojo y las adiciones en verde. Es una demostración sencilla; el resto del artículo explica cómo funciona y cuándo puede ser útil.
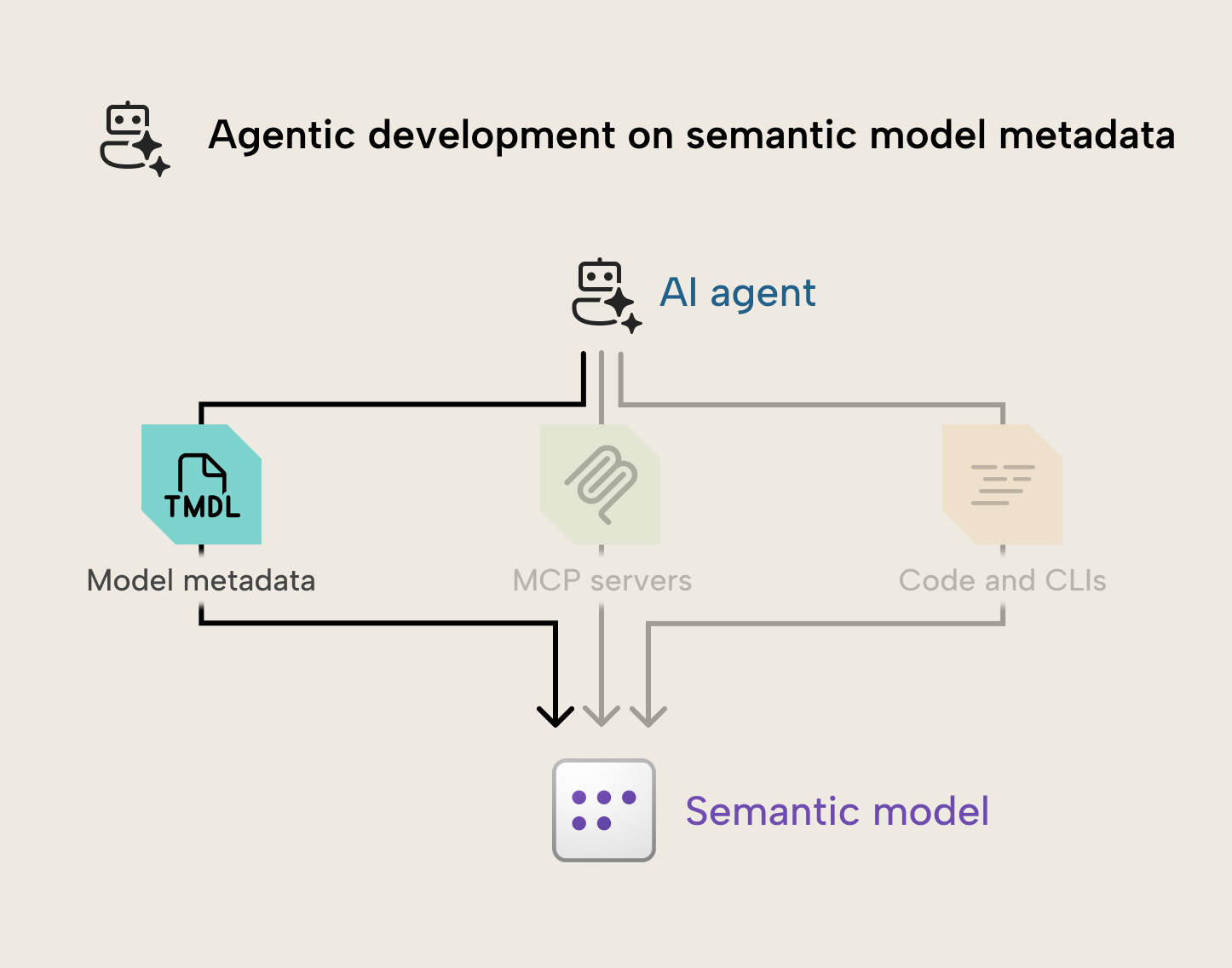
Cómo funciona: el diagrama del escenario
Este enfoque implica que el agente use herramientas de lectura y escritura para cambiar directamente los archivos de metadatos del modelo semántico. El siguiente diagrama ofrece una visión general sencilla de cómo podrías usar un agente para hacer cambios directamente en los metadatos del modelo:
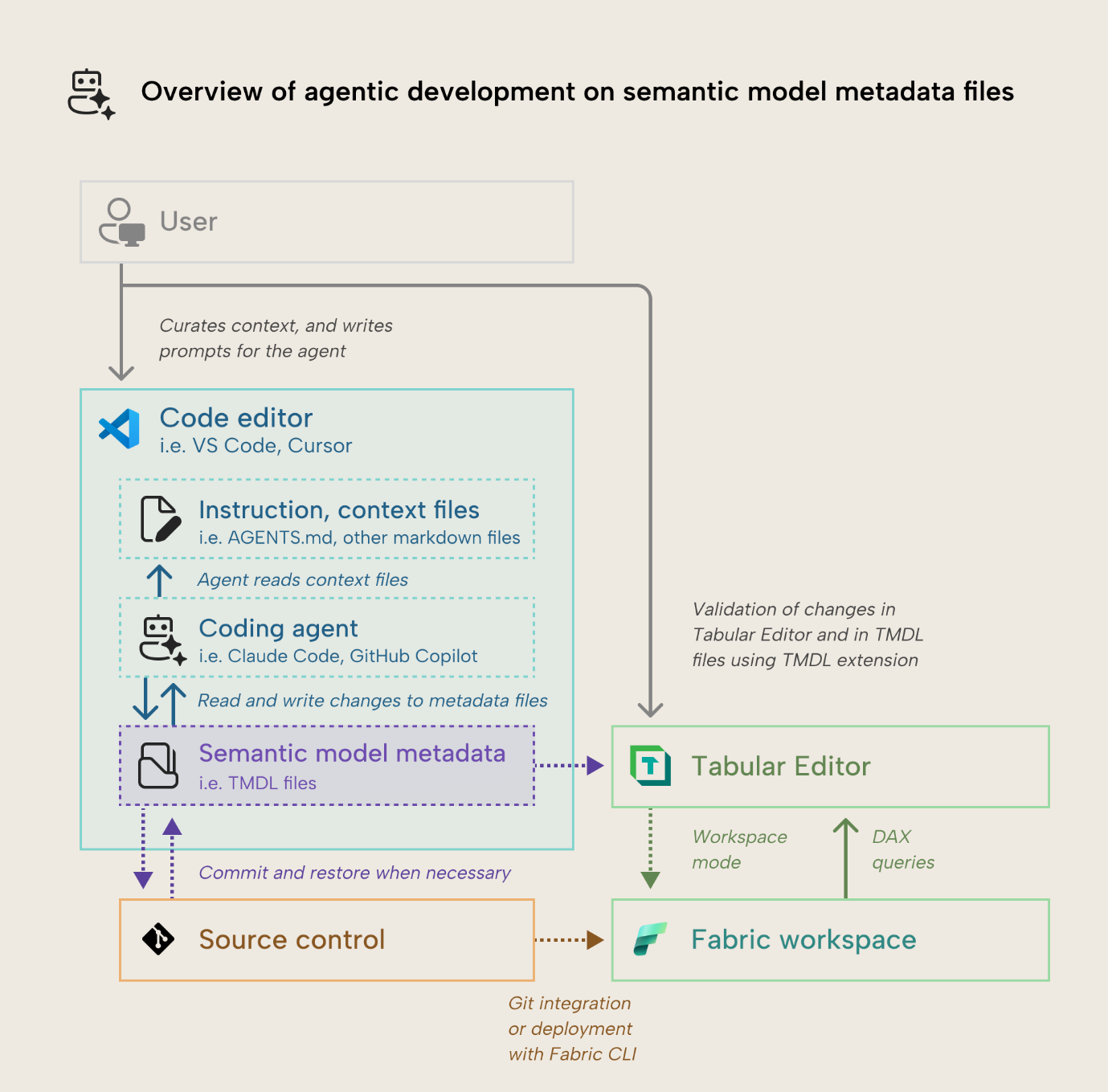
Puedes entender este proceso así:
- Guarda un archivo de Power BI Desktop (.pbix) como un Proyecto de Power BI (PBIP), o guarda la definición del modelo semántico en formato model.bim, database.json o TMDL. Esto te permite ver y modificar los metadatos del modelo semántico.
- Ve los metadatos del modelo semántico en un editor de código como VS Code o Cursor. Este paso es opcional, pero recomendable, para que puedas usar el editor para ver y gestionar los archivos, así como sus cambios mediante control de código fuente hacia un repositorio remoto.
- Prepara un conjunto base de instrucciones (como AGENTS.md o CLAUDE.md) y contexto (otros archivos .md) sobre el formato TMDL y el modelo semántico que quieres cambiar. Opcionalmente, también puedes configurar otras herramientas y componentes basados en agentes, según el agente de codificación que uses, como el servidor MCP remoto de Microsoft Docs o una habilidad de Claude Code. Preparar estas instrucciones y este contexto no es una tarea puntual: requiere una revisión y un mantenimiento continuos; se parece más a una habilidad de comunicación y redacción que a una habilidad técnica.
- Crea un prompt o elabora un plan con el agente de codificación. Esto se hace mejor como un ejercicio iterativo con el agente de codificación antes de que realice cualquier cambio. El contexto, las instrucciones y los prompts no los genera la IA ni los crean los agentes, ya que esto puede empeorar el rendimiento.
- Envía el prompt para iniciar una sesión.
- El agente ingiere sus instrucciones en la ventana de contexto, que es el presupuesto finito de tokens que puede tener en una sesión activa. Con sus herramientas, lee otros archivos de contexto y los metadatos del modelo semántico, según el prompt. El agente también puede usar otras herramientas para recuperar información adicional de otros archivos, de la web o de tu entorno de Fabric.
- Finalmente, el agente usa una herramienta de escritura para hacer cambios directos en los metadatos del modelo. Según el modelo y el agente, estos cambios ocurren a un ritmo distinto. Algunos agentes pueden hacer muchos cambios en paralelo, y algunos modelos ofrecen más rendimiento que otros.
- El usuario supervisa los cambios del agente. Según el agente y el editor de código que uses, tendrás distinta visibilidad y distintas funciones para ayudarte.
- Al final, el agente deja de hacer cambios. Puedes validar esos cambios en el editor de código con la ayuda de la extensión de TMDL. También puedes usar Tabular Editor para cargar los metadatos del modelo y ver los cambios en un entorno de desarrollo integrado (IDE) para modelos semánticos. Algunos cambios pueden producir archivos de metadatos no válidos, que hay que ajustar, o tendrás que volver a una versión anterior del código mediante un punto de control (una función del agente) o un commit (si estás usando control de código fuente).
- Si usas Tabular Editor 3, puedes usar el modo del área de trabajo para sincronizar cualquier cambio local con un modelo semántico publicado, que puedes procesar y consultar para validar esos cambios. Como alternativa, puedes configurar el agente de codificación para que despliegue automáticamente el modelo en un Workspace de pruebas, lo procese y lo consulte a través del agente.
NOTA
El diagrama se centra en un escenario local y supervisado en el que un único agente opera bajo orquestación humana. También puedes ejecutar varios agentes en paralelo.
Además, puedes delegar agentes no supervisados en segundo plano, como GitHub Copilot, Claude Code en la web o Google Jules, que trabajan en una rama independiente de tu repositorio dentro de un contenedor. Puede que hablemos de estos escenarios no supervisados en un artículo aparte más adelante.
Demostraciones: cómo se ve en la práctica
Para hacerlo más concreto, aquí tienes algunos ejemplos de agentes trabajando con metadatos de modelos semánticos:
Desarrollo con agentes usando GitHub Copilot
GitHub Copilot es un agente de codificación que puedes usar desde la interfaz de usuario de VS Code. Puedes usar GitHub Copilot en modo agente para realizar cambios específicos en archivos. Por ejemplo, aquí puedes añadir descripciones a tablas y medidas, basándote en una plantilla o en un conjunto de ejemplos.
En el vídeo, ves cómo GitHub Copilot añade descripciones a medidas y columnas de una tabla (Budget.tmdl) basándose en un ejemplo y en un prompt. Este es un escenario habitual que muchos ya han explorado con un amplio abanico de enfoques.
Desarrollo agéntico con Claude Code
Claude Code funciona de forma similar a GitHub Copilot. También tiene una interfaz de usuario mediante la extensión de Claude Code. A continuación tienes un ejemplo de Claude Code buscando en el modelo posibles motivos que expliquen por qué hay valores (Blank) en un Report de Power BI:
Como puedes ver, Claude Code puede explorar los metadatos del modelo en función del prompt y las instrucciones, que explican qué es la integridad referencial, por qué ocurre y cómo validarla. Encuentra el problema: un filtro en la partición de la tabla Products que excluye productos de un determinado tipo. Fíjate en que hace varias sugerencias poco óptimas (como proponer un filtro incorrecto de la tabla de hechos) antes de quitar el filtro de Products.
Sin embargo, lo más habitual es que Claude Code funcione en el terminal. Puedes abrir un terminal en el editor de código o en una ventana aparte, e interactuar con el agente de programación como lo harías con un chatbot normal. Aquí puedes ver cómo Claude Code añade una función al modelo y, después, refactoriza las medidas para que utilicen esa función:
En la demostración, también puedes ver cómo el usuario valida los cambios tanto en los archivos TMDL como en Tabular Editor 3. Con Tabular Editor 3, el usuario puede usar Code Assist para identificar cualquier problema de sintaxis de DAX y también consultar el modelo para validar que los cambios producen los resultados esperados.
El resto de este artículo explica cómo configurarlo, sus pros y contras, y algunos consejos para que te vaya bien.
Cómo empezar
Este enfoque es el más fácil de configurar y usar, ya que no requiere ningún software adicional aparte del editor de código y el agente. Sin embargo, la mayoría de los agentes de programación sí requieren licencias aparte. Si es un enfoque que quieres explorar, necesitas lo siguiente:
- Guarda tu archivo de Power BI Desktop (.pbix) usando el formato de Proyecto de Power BI (PBIP). El formato PBIP guarda el modelo y el Report en carpetas de proyecto independientes, que contienen todos los archivos de metadatos que puedes leer y escribir. Sin el formato PBIP, no se admite hacer cambios en los metadatos del modelo, y no puedes hacer seguimiento de los cambios en objetos individuales del modelo. Como alternativa, puedes guardar la definición de tu modelo semántico usando los formatos model.bim (TMSL), Database.json (el “Guardar en carpeta” de Tabular Editor) o TMDL. Recomendamos el formato TMDL para el desarrollo agéntico de ahora en adelante, pero model.bim y Database.json también funcionan bien, por ahora.
- Un agente de programación que puedas usar como GitHub Copilot en modo agente, Claude Code o Gemini CLI. La mayoría de los agentes de programación requieren una suscripción de pago para poder usarlos. Recomendamos Claude Code, que creemos que ofrece las mejores funciones y la mejor experiencia de desarrollador para el desarrollo agéntico en Microsoft Fabric, Power BI y, en general.
- Un repositorio remoto donde puedas configurar control de versiones para tu modelo semántico. El control de versiones es esencial para el desarrollo agéntico, para mitigar los efectos de operaciones destructivas y poder hacer seguimiento y gestionar los cambios de tu trabajo (y revertirlos, si es necesario). La mayoría de los agentes de programación admiten “checkpoints” para esto, pero deberías usarlos como complemento, además del control de versiones.
- Un entorno de desarrollo integrado en el que puedas cargar y explorar fácilmente tu modelo (como Tabular Editor 2 o 3) y un editor de texto donde puedas manipular los archivos (como VS Code).
NOTA
No necesitas Microsoft Fabric, Premium-Per-User, ni siquiera Power BI Pro para este enfoque, ya que estás modificando archivos de metadatos locales.
En qué se diferencia este enfoque de otros
Este enfoque se diferencia un poco de los otros tres, ya que el agente lee y modifica los metadatos directamente. Cuando un agente usa un servidor MCP o una CLI, lo hace de forma indirecta, a través del código. De ahí se desprenden algunas ventajas y retos clave.
Ventajas de este enfoque
Este enfoque tiene algunas ventajas únicas:
- Búsqueda: La mayor ventaja de este enfoque es que es la forma más rápida y eficiente de que la IA busque o resuma un modelo semántico. Tanto si el agente de programación usa una herramienta Read , una herramienta Bash o una búsqueda semántica más compleja, puede revisar mucho más rápido los archivos locales para encontrar una palabra o un patrón concreto, manteniendo al mínimo el consumo de tokens.
- Más fácil “deshacer” cambios: Cuando modificas archivos de metadatos del modelo, es más fácil volver a un checkpoint o commit anterior. Cuando haces cambios en un modelo local abierto en Power BI Desktop o en un modelo publicado en el servicio, esto es mucho más difícil. Esto es, de hecho, una ventaja enorme, porque si “rompes” tu modelo o realizas una operación destructiva, puedes meterte en problemas si trabajas directamente sobre un modelo semántico local o remoto en lugar de sobre sus metadatos.
- Simplicidad: Como básicamente solo estás modificando archivos de texto, es fácil entender qué está haciendo el agente y qué cambios hizo. Tampoco necesitas instalar nada, y mejorar el rendimiento del agente simplemente consiste en mejorar tus archivos de contexto y tus prompts.
- Seguridad: Como no dependes de que el agente ejecute código arbitrario ni de que use herramientas de servidor MCP, hay menos riesgo con este enfoque. Además, puede ser más sencillo hacerlo más seguro o privado, ya que puedes confinar al agente en un contenedor o incluso usar un LLM local sin depender de la generación de código del modelo ni de su capacidad de invocar herramientas.
- Modularidad: Puedes combinar este enfoque con otros. Por ejemplo, los agentes pueden usar servidores MCP y código para manipular los metadatos del modelo, en lugar de escribir en ellos directamente. Puede haber casos en los que sea más rápido o más fácil modificar el archivo (por ejemplo, cambios únicos) y casos en los que no, así que el agente puede usar un servidor MCP o código.
A pesar de su simplicidad, este enfoque suele ser el que más salvedades y limitaciones tiene.
Retos de este enfoque
Hay varios retos para el desarrollo agéntico, aquí:
- Dificultad para validar cambios: La mayor salvedad al modificar archivos locales es que no puedes consultarlos ni probar cómo los cambios alteran los datos o los cálculos. Para eso, primero tienes que abrir el modelo en Power BI Desktop o publicarlo en un Workspace, y procesarlo. Puedes simplificar o incluso automatizar esto (por ejemplo, usando Tabular Editor 3 en modo del área de trabajo o usando la Fabric CLI). Además, si los cambios dan como resultado un TMDL no válido, es difícil validarlo solo con los archivos (incluso con la extensión de TMDL). Otros enfoques restringen las operaciones posibles, lo que limita que esto ocurra.
- Fragilidad: Como el agente solo modifica archivos de texto directamente, puede cometer errores con facilidad y terminar generando un TMDL no válido. Por ejemplo, TMDL es sensible a los espacios en blanco; la indentación y cambios de sintaxis aparentemente inocuos pueden dar lugar a archivos no válidos.
- Complejidad: TMDL es único porque contiene tres o más sintaxis diferentes. Un archivo TMDL puede contener metadatos del modelo semántico, además de expresiones DAX, expresiones de Power Query (M) y, en raras ocasiones, otras sintaxis (como SQL para consultas nativas, o Python y R con la integración de Power Query). Estas sintaxis incrustadas pueden confundir fácilmente al agente, haciendo que aparezca sintaxis TMDL dentro de una expresión DAX grande, o al revés.
- Nuevos formatos de metadatos: TMDL y PBIR son formatos nuevos y tienen poca presencia en los datos de entrenamiento de los LLM. Incluso puede que descubras que los modelos pueden generar o gestionar mejor TMSL y los metadatos de Report heredados que TMDL y PBIR. Por eso, tienes que dedicar más esfuerzo a crear y mantener el contexto para trabajar con estos formatos correctamente.
- Ineficiente o lento: Con este enfoque, estás esperando a que el agente encuentre el objeto o la propiedad que quieres cambiar y luego genere el valor correcto para modificarlo. Además, necesitas validarlo en un programa que “construya” el modelo a partir de los metadatos. Para muchos cambios simples y la mayoría de las incorporaciones, esto simplemente tardará mucho más (y costará mucho más) que hacer los cambios tú mismo. Esto se vuelve útil cuando los patrones son consistentes, pero los valores no lo son (como descripciones, carpetas de visualización o expresiones). Esto es especialmente cierto en modelos semánticos más grandes y complejos.
- Poco fiable para generar archivos y propiedades nuevos: Generar archivos .tmdl completamente nuevos es un proceso largo en el que hay una alta probabilidad de que el LLM cometa un error.
- Degradación del contexto: Si el agente tiene que leer los metadatos del modelo antes de hacer cambios cada vez, puede consumir muchos tokens y llenar la ventana de contexto. Esto puede reducir el rendimiento y aumentar el coste, o hacer que alcances antes los límites de sesión. Esto es especialmente cierto en tablas con muchas medidas y columnas, ya que todo esto se define en el archivo .tmdl de esa tabla concreta.
A pesar de estos retos, aún hay algunos casos en los que este podría ser tu enfoque preferido.
Cuándo podrías usar este enfoque
Hay algunos casos en los que podrías preferir este enfoque frente a otros:
- Buscar o explorar un modelo, sobre todo si es un modelo que no has creado tú. Esto debería hacerse en paralelo con explorarlo en otra herramienta como Tabular Editor o Power BI Desktop, donde puedes ver mejor los objetos distintos y cómo se relacionan entre sí, por ejemplo en un diagrama del modelo. Algunos ejemplos serían buscar un patrón de código concreto, una columna o una propiedad, especialmente si puedes describirlo de forma aproximada sin conocer el nombre o el valor exactos.
- Ajustes simples o puntuales que no son fáciles de hacer con una interfaz de usuario o con scripting. Por ejemplo, refactorizar valores simples de propiedades existentes (como nombres de carpetas de visualización) o quitar parte de una expresión DAX o Power Query (como un filtro) presente en múltiples instancias.
- Ajustar en bloque nombres de objetos o valores de propiedades que ya están establecidos. Por ejemplo, renombrar o refactorizar objetos. Ten en cuenta que, cuando necesitas modificar propiedades de varias líneas, incluso cambios simples pueden volverse problemáticos, porque TMDL es sensible a los espacios en blanco y a las tabulaciones.
Cuándo quizá no deberías usar este enfoque
También hay algunos casos en los que este enfoque no es preferible, y deberías usar en su lugar servidores MCP, interfaces programáticas o desarrollo tradicional:
- Cambios con dependencias. Muchos cambios que podrías hacer en los metadatos del modelo pueden tener efectos en objetos posteriores. Ejemplos sencillos son cambiar el nombre de tablas, columnas o medidas, que puede que no se renombren en las expresiones que las referencian. También puedes encontrarte con problemas si modificas propiedades que requieren un nivel de compatibilidad del modelo más alto, o que interactúan con propiedades y anotaciones menos documentadas.
- Añadir propiedades y objetos nuevos. Cuando tienes que añadir tablas, medidas y columnas nuevas al modelo, hay más posibilidades de que el agente se equivoque con la sintaxis o la indentación de TMDL.
- Cambios que requieren validación. Los cambios en expresiones DAX y Power Query pueden ser problemáticos con los metadatos del modelo, porque no recibes ninguna indicación de si la sintaxis es correcta.
Estos son solo algunos ejemplos. En resumen, trabajar con archivos de metadatos suele ser más rápido y eficiente para operaciones de lectura y resumen, o para cambios simples en objetos y propiedades existentes. Para la mayoría de los demás casos, te conviene usar enfoques alternativos.
Consejos para tener éxito con agentes en archivos TMDL
A pesar de su simplicidad, aún hay muchas cosas que tener en cuenta con este enfoque. Es muy fácil acabar con malos resultados o perder mucho tiempo, especialmente si no inviertes en un buen contexto o usas modelos lentos.
- Usa checkpoints y control de versiones: Es extremadamente importante que puedas revertir cambios rápida y fácilmente cuando estás haciendo desarrollo agéntico. Esta es una ventaja clave de este enfoque; no la desaproveches ni te arriesgues a romper o perder trabajo importante.
- Usa modelos más rápidos, con más tokens por segundo (tps): Modelos como Composer de Cursor o Haiku 4.5 de Anthropic funcionan mejor para este enfoque. Estos modelos tienen un rendimiento muy alto y, aun así, una precisión decente y buena capacidad para seguir instrucciones. Esto ayuda a compensar la ineficiencia de tener que esperar a que el modelo haga cambios en los archivos.
- El contexto lo es todo: No lograrás resultados consistentes con este enfoque a menos que inviertas en crear buenas instrucciones y prompts. Es una inversión inicial que puede llevar tiempo, pero puede merecer la pena.
- Usa el servidor MCP de Microsoft Docs o las herramientas WebSearch / Fetch: Puedes indicar al agente que recupere información sobre los formatos de metadatos e incluso sobre los modelos semánticos en general. Es un consejo útil, independientemente del enfoque que elijas, pero resulta especialmente útil si los agentes van a trabajar directamente con metadatos.
- Usa la TMDL extensión en VS Code: La extensión TMDL ofrece resaltado de sintaxis y cierta validación para facilitar el trabajo con TMDL. Algunos agentes de codificación que se integran con tu IDE también pueden aprovechar la extensión para ver esta validación y mejorar sus salidas.
- Valida en cada sesión: Después de realizar modificaciones con un agente de programación, no deberías limitarte a leer los archivos TMDL. Deberías abrir el modelo en una herramienta funcional para ver realmente los cambios e identificar cualquier error o advertencia. Por ejemplo, si abres tu modelo en Tabular Editor, las advertencias y los errores del análisis semántico te avisarán de los problemas, y también puedes usar el Best Practice Analyzer y otras herramientas para encontrar incidencias que resolver.
- Considera cómo integrarlo con CI/CD: Una de las mayores carencias de este enfoque es que no puedes consultar el modelo después (o mientras) haces cambios para validarlos. Una forma de gestionarlo es configurar procesos para desplegar automáticamente (y reprocesar) el modelo al final de una sesión en un Workspace de pruebas. Luego, puedes usar otras herramientas como servidores MCP o el Fabric CLI para consultar el modelo.
- No uses este enfoque en solitario; combínalo con otros: Para obtener los mejores resultados, deberías combinar este enfoque con servidores MCP o con herramientas de código, API o CLI. Así, puedes aprovechar enfoques programáticos para operaciones masivas más eficientes, sin renunciar a búsquedas y resúmenes rápidos del modelo, o a modificaciones de un solo archivo.
- Mantén los metadatos de tu modelo abiertos en Tabular Editor: Tabular Editor puede recargar los metadatos del modelo después de cada cambio y ayudarte a validar los cambios. Con Tabular Editor 3, te beneficias del análisis semántico y de Code Assist para DAX, además de la detección automática de infracciones de buenas prácticas y del Optimizador de DAX para encontrar cuellos de botella. Con el modo del área de trabajo, también puedes asegurarte de que tu modelo esté actualizado en un Workspace para poder consultarlo. Si prefieres no usar Tabular Editor, reiteramos que deberías configurar algún tipo de despliegue automatizado con el Fabric CLI a un Workspace.
- Usa un agente que se ejecute en la terminal: Puede que obtengas resultados mejores y más rápidos con agentes de línea de comandos como Claude Code o GitHub Copilot CLI, frente a agentes que tienen una interfaz de usuario. Esto se basa únicamente en la experiencia subjetiva del autor.
Estas son solo algunas cosas a tener en cuenta.
Mantendremos este artículo al día a medida que evolucione este ámbito; puedes guardarlo como Bookmark y volver a consultarlo de vez en cuando.
En conclusión
Un enfoque para el desarrollo con agentes consiste en modificar directamente los archivos de metadatos del modelo. Este enfoque es el más sencillo de configurar y usar, pero también es el que tiene más advertencias: una gran dependencia de un buen contexto y buenos prompts, dificultad para validar resultados y retos específicos como los espacios en blanco en TMDL. Sin embargo, también es el enfoque más rápido y eficiente para que un agente busque y explore el modelo, y la forma más directa de usar agentes asíncronos (o en segundo plano) trabajando sin supervisión, ya sea para revisar o para trabajar en funcionalidades específicas.
El siguiente artículo de esta serie trata un segundo enfoque, en el que le das a un agente un servidor del Model Context Protocol (MCP) para manipular los metadatos del modelo.


