
此内容由人工智能翻译,尚未经过人工编辑审核。图像和图表保持其原始语言。
关键要点
- 本文为系列文章之一。 从第一篇开始:点此阅读。
- 代理可以直接修改模型元数据,例如 TMDL 文件。 采用这种方式时,代理会在本地元数据文件上工作,读取并写入更改。 无监督代理也可以在远程 repository 中处理元数据文件。
- 这种方法很简单,还能让你从版本控制中获益。其主要优势在于上手容易、检索/汇总效率高,并且可借助检查点和版本控制来回滚更改。
- 不过,元数据文件很脆弱,也很难验证。 如果没有良好的指令和提示词,代理很容易对语义模型元数据做出破坏性更改。 在查询之前,你还必须先部署模型元数据,或在 Power BI Desktop 中打开它。 读取或写入模型元数据也可能成本高、速度慢。
- 将这种方式与其他方法结合,并制定验证策略。当你将它与 MCP 服务器或代码结合使用时,往往能更好地发挥各自优势。 你应在 Tabular Editor 中(借助 Code Assist、工作区模式和其他功能)验证这些更改,或通过设置自动化部署到 Workspace 来进行验证。
本摘要由作者撰写,并非由 AI 生成。
使用代理修改模型元数据
本系列会带你了解如何用 AI 通过代理来推动语义模型变更的不同方法。 语义模型代理具备工具,使其能够读取、查询并写入对语义模型的更改。 以这种方式使用代理称为 代理式开发,在某些场景下,它可以有效补充传统的开发工具与工作流。
AI 可以通过多种方式对语义模型进行更改,包括修改元数据文件、使用 MCP 服务器或编写代码。 每种方式都有利弊。如果你打算用 AI 来修改语义模型,那么你很可能会三种方式都用到。
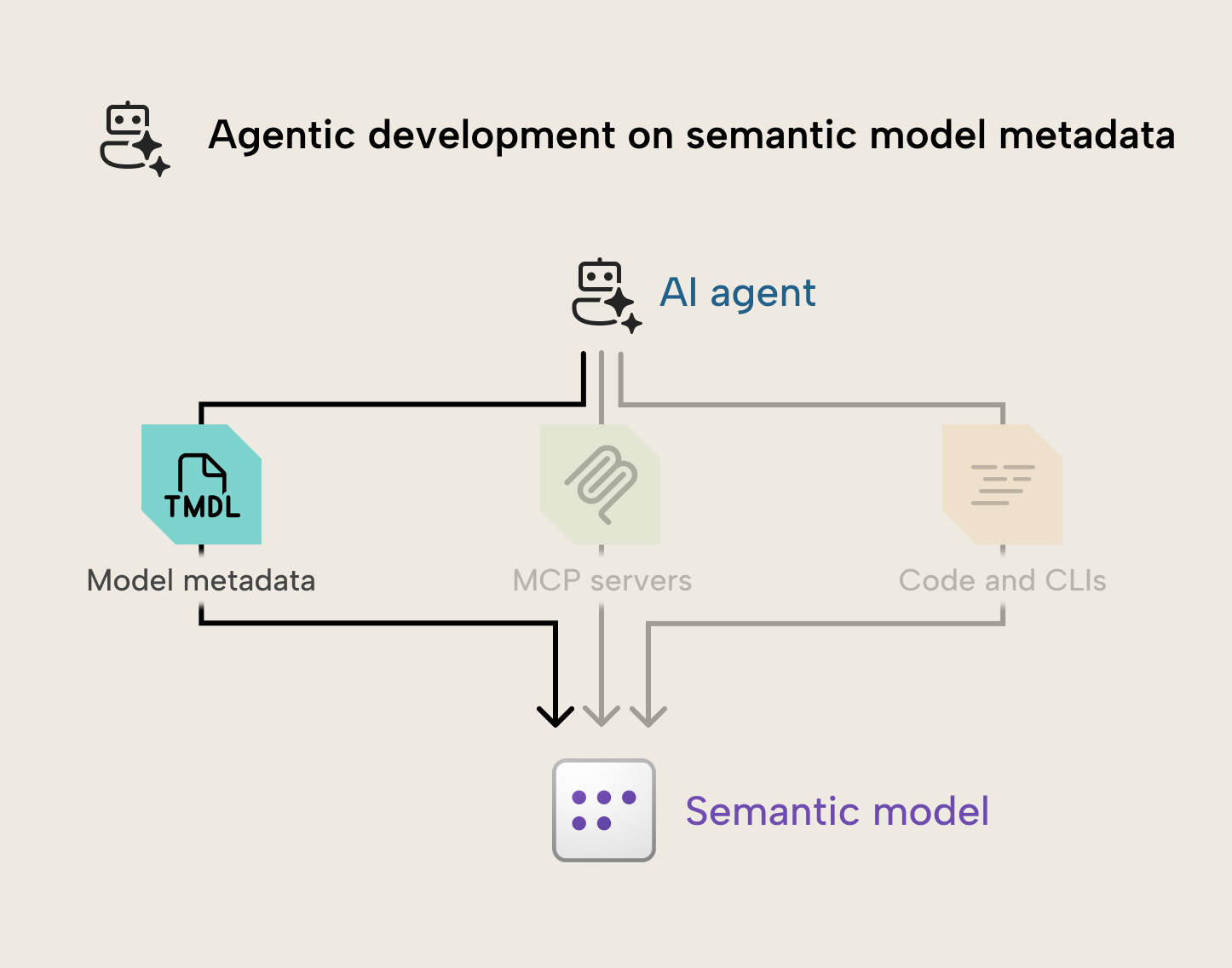
在本文中,我们将探讨如何使用编程代理直接读取与写入模型元数据文件的更改,包括这种方式的优缺点,以及基于我们目前经验总结的实用建议。
提示
本文重点介绍编程代理通过其内置工具直接修改元数据的方式。 正如你在本系列后续文章中将看到的,我们目前建议使用 powerbi-modelling-mcp 或 TE2 CLI,并与 TMDL 模型元数据配合使用。这样既能为编程代理提供一种高效的、可编程方式来建模元数据,又能保留对元数据的直接访问能力。 这也能让你更容易通过源代码管理查看并跟踪更改。
什么是模型元数据?
当你创建并保存语义模型时,所有结构、计算和属性都会保存在 Power BI Desktop 或 Power BI Project (PBIP) 文件的元数据中。 这也称为语义模型定义。 如果你将模型保存为 PBIP 格式,就可以在文本或代码编辑器中打开并查看这些元数据。 我们建议使用 VS Code 或 Cursor。
如果你对 PBIX 与 PBIP 格式不熟悉,这张来自 微软文档 的图片解释了二者差异:
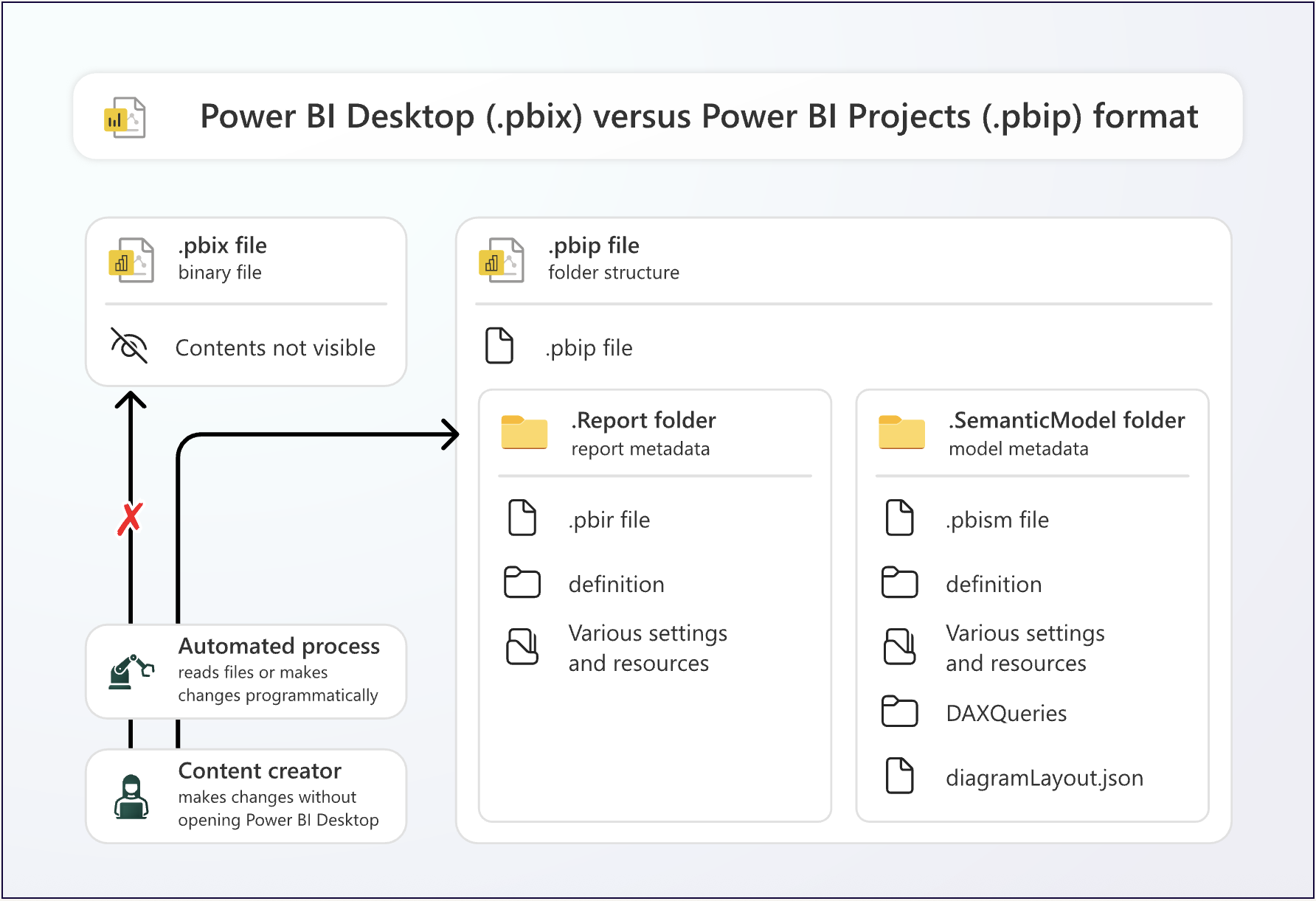
模型元数据位于 .SemanticModel 文件夹 中;更具体地说,是“definition” 文件夹。 熟悉这些元数据有很多好处,例如便于自动化、通过 源代码管理 更好地跟踪更改,以及使用 Git 集成。 下面示例展示了语义模型元数据的样子,如果你使用新的 Tabular Model Definition Language (TMDL) format 保存:
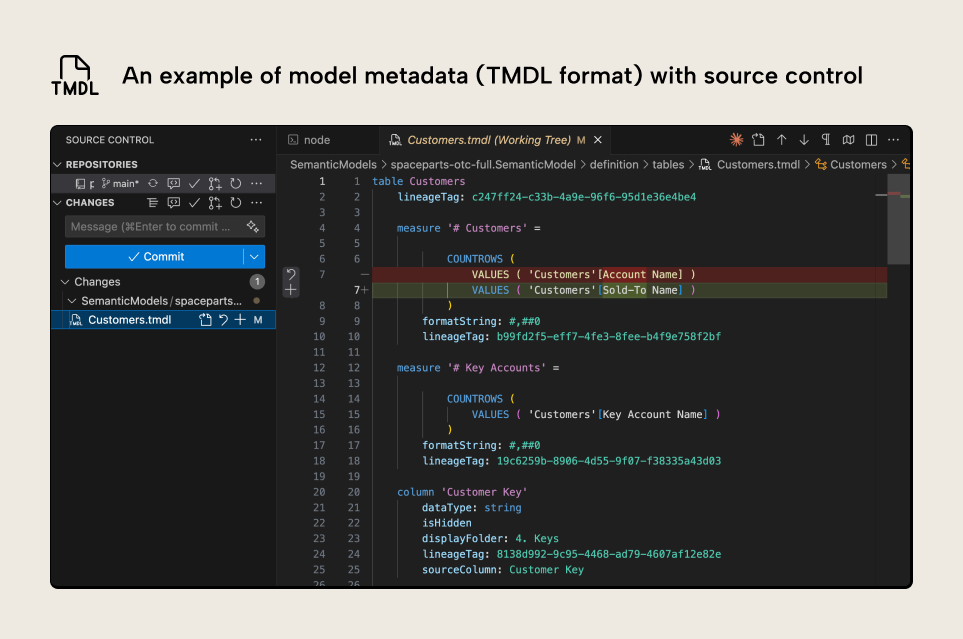
图片展示了语义模型表 Customers 的元数据,包括该表中度量值与列的元数据。 语法高亮由 TMDL 扩展 提供,可在 VS Code 和 Cursor 中使用。 # Customers 度量值已发生更改。 红色显示的是之前的表达式,绿色显示的是新的表达式。
这个示例说明,即便是很细微的改动也清晰可见;此外,你还可以直接修改模型元数据,从而对你的模型功能产生影响。 手动做这件事既繁琐,又容易出错。 不过,当你让一个编码智能体替你修改模型元数据时,事情就变得有意思多了。
下面先快速演示一下这种方法的实际效果:
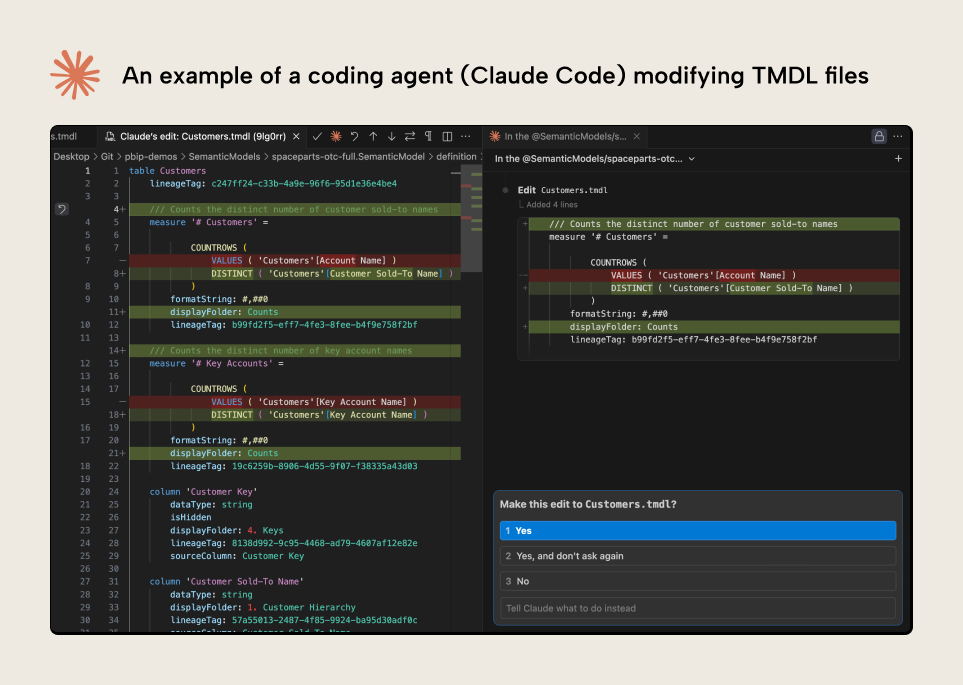
演示中,编码智能体(Claude Code)在 VS Code 内读取并修改语义模型元数据。 智能体会先征求你的同意再进行修改:删除项用红色标出,新增项用绿色标出。 这只是一个简单演示;本文的其余部分将解释它如何工作,以及它在什么情况下可能有用。
工作原理:场景示意图
这种方法是让智能体使用读写工具,直接更改语义模型元数据文件。 下图展示了如何使用智能体直接修改模型元数据的简单概览:
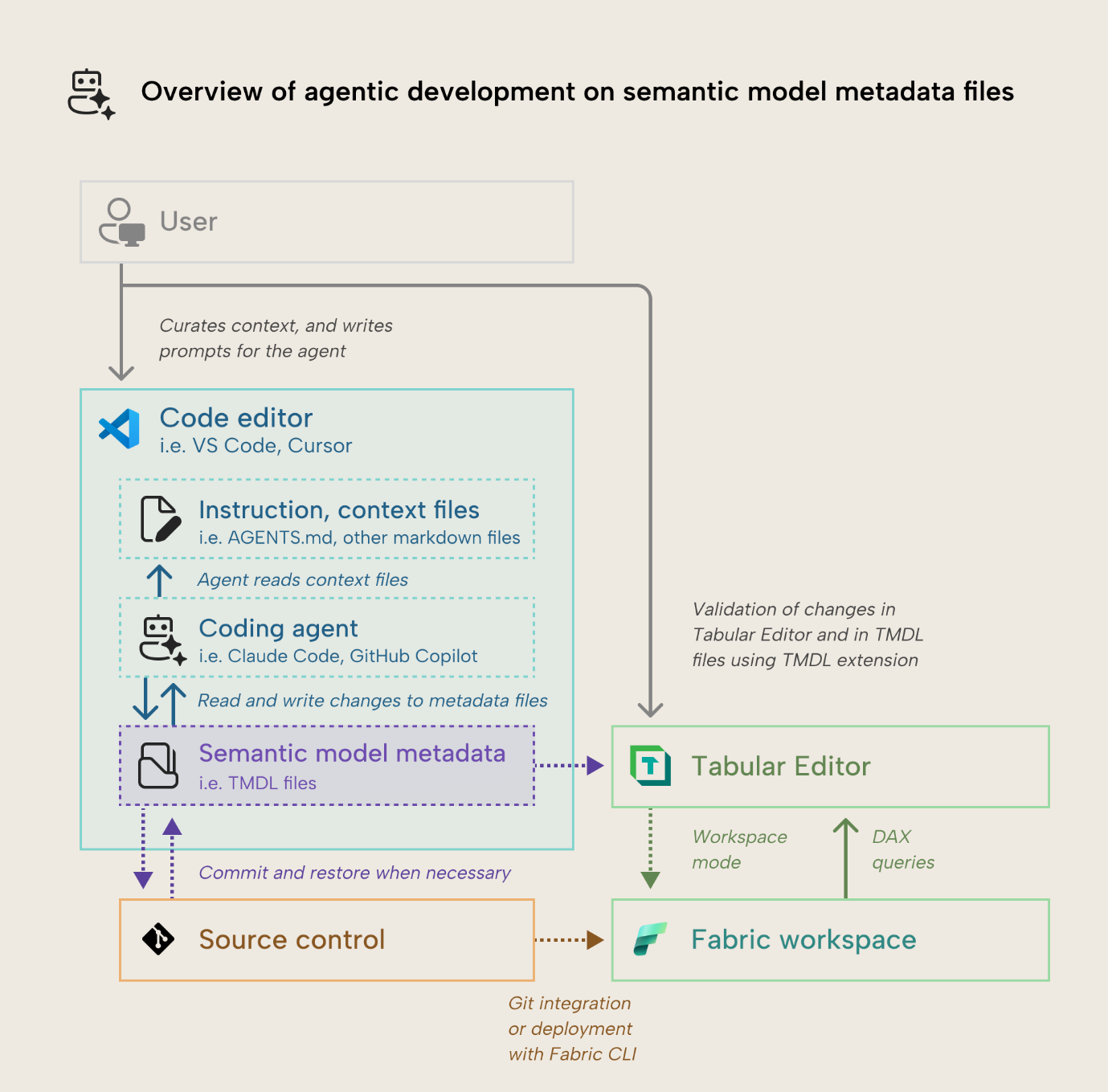
你可以这样理解这个过程:
- 你将 Power BI Desktop (.pbix) 文件另存为 Power BI Project (PBIP),或将语义模型定义保存为 model.bim、Database.json 或 TMDL 格式。 这样你就可以查看并修改语义模型元数据。
- 你在 VS Code 或 Cursor 这类代码编辑器中查看语义模型元数据。 这是一个可选但推荐的步骤,这样你就能用编辑器查看和管理文件,并通过版本控制将变更提交到远程 repository。
- 你整理一套基础说明(例如 AGENTS.md 或 CLAUDE.md)以及上下文(其他 .md 文件),用于描述 TMDL 格式和你想要修改的语义模型。 你也可以根据所用的编码智能体按需配置其他智能体工具和组件,例如 Microsoft Docs 远程 MCP 服务器或 Claude Code 的某项技能。 这些说明和上下文的搭建不是一次性工作,需要持续整理与维护;它更像是一种沟通与写作能力,而不是技术能力。
- 你和编码智能体一起创建提示词或起草计划。 最好以迭代的方式与编码智能体共同完成,在它进行任何更改之前先对齐思路。 上下文、说明和提示词不应由 AI 生成或由智能体创建,否则可能导致性能下降。
- 用户提交提示词以启动会话。
- 智能体将其说明加载到上下文窗口中——这是一场活动会话里可用的有限 token 预算。 它会根据提示词,使用工具读取其他上下文文件以及语义模型元数据。 智能体也可能使用其他工具,从其他文件、网页或你的 Fabric 环境中检索额外信息。
- 最终,智能体会使用写入工具直接更改模型元数据。 变更的速度因模型和智能体而异。 有些智能体可以并行完成大量更改,而有些模型的吞吐量也高于其他模型。
- 用户监督智能体的更改。 根据智能体和所用代码编辑器的不同,你能获得的可见性和支持功能也不同。
- 最终,智能体停止更改。 你可以在代码编辑器中借助 TMDL 扩展来验证这些更改。 你也可以使用 Tabular Editor 加载模型元数据,在语义模型的集成开发环境中查看这些更改。 有些更改可能会导致元数据文件无效,这时必须进行调整;或者你需要通过 checkpoint(智能体的一个功能)或 commit(前提是你在使用源代码管理)回退到之前的代码版本。
- 如果你用的是 Tabular Editor 3,就可以使用工作区模式将本地更改同步到已发布的语义模型,然后对它进行处理并发起查询,以验证这些更改。 或者,你也可以配置编码智能体,让它自动将模型部署到沙盒 Workspace 工作区,完成处理,并通过智能体对其发起查询。
注意
该图重点展示了一个本地、有人监督的场景:单个智能体在人类的编排下运行。 你也可以并行运行多个智能体。
此外,你还可以将无人监督的智能体委派到后台,例如 GitHub Copilot、网页端的 Claude Code 或 Google Jules;它们会在容器中,在你 repository 的独立分支上工作。 我们可能会在以后用单独的文章来讨论这些无人监督的场景。
演示:实际效果是什么样的
为了更具体一些,下面给出几个智能体处理语义模型元数据的不同示例:
使用 GitHub Copilot 的智能体开发
GitHub Copilot 是一个编码智能体,你可以在 VS Code 的用户界面中使用它。 你可以在智能体模式下使用 GitHub Copilot,对文件进行特定修改。 例如,在这里,你可以根据模板或一组示例,为表和度量值添加说明。
在视频中,你会看到 GitHub Copilot 基于示例和提示词,为某个表(TMDL 文件 Budget.tmdl)中的度量值和列添加说明。 这是一个很常见的场景,很多人已经用各种不同的方法探索过。
使用 Claude Code 进行智能体开发
Claude Code 的工作方式与 GitHub Copilot 类似。 它还通过 Claude Code 扩展提供用户界面。 下面这个示例展示了 Claude Code 如何搜索模型,找出可能的原因,用来解释为什么 Power BI Report 中会出现 (Blank) 值:
如你所见,Claude Code 可以根据提示词和指令探索模型元数据,并说明参照完整性是什么、为什么会发生,以及如何验证。 它找到了问题:Products 表的分区中有一个筛选器,把某一类型的产品排除了。 注意,在它从 Products 中移除筛选器之前,会先给出几个不太理想的建议(比如建议对事实表使用一个不正确的筛选器)。
不过更多情况下,Claude Code 是在终端中运行的。 你可以在代码编辑器里打开终端,也可以在单独的窗口中打开,然后像使用普通聊天机器人一样与这个编码智能体交互。 在这里你可以看到 Claude Code 向模型添加一个函数,然后重构度量值以使用该函数:
在演示中,你还可以看到用户同时在 TMDL 文件和 Tabular Editor 3 中验证这些更改。 借助 Tabular Editor 3,你可以使用 Code Assist 找出任何 DAX 语法问题,也可以查询模型来验证这些更改是否产生了预期结果。
本文后续会说明你怎么为自己搭建这一套方案、它的优缺点,以及一些成功实践的建议。
如何开始
这种方式最容易搭建和使用,因为除了代码编辑器和智能体之外,不需要额外的软件。 不过,大多数编码智能体确实需要单独的许可证。 如果你想探索这种方式,你需要准备以下内容:
- 将 Power BI Desktop (.pbix) 文件保存为 Power BI Project(PBIP)格式。 PBIP 格式会将你的模型和 Report 分别保存到不同的项目文件夹中,其中包含所有可读写的元数据文件。 如果不使用 PBIP 格式,就不支持对模型元数据进行更改,而且你也无法跟踪单个模型对象的变更。 另外,你也可以用 model.bim (TMSL)、Database.json(Tabular Editor 的“保存到文件夹”)或 TMDL 格式来保存语义模型定义。 我们建议今后用于智能体开发时优先采用 TMDL 格式,但目前 model.bim 和 Database.json 也同样好用。
- 一个编码智能体,可像使用 GitHub Copilot 的 Agent 模式、Claude Code 或 Gemini CLI 那样来使用。 大多数编码智能体都需要付费订阅才能使用。 我们推荐 Claude Code;我们认为它在 Microsoft Fabric、Power BI 以及整体智能体开发方面,功能最完善、开发者体验也最佳。
- 一个远程仓库,用于为你的语义模型配置源代码管理。 源代码管理对智能体开发至关重要:它能缓解破坏性操作带来的影响,让你可以跟踪和管理对工作的更改(必要时还能回退这些更改)。 大多数编码智能体也支持用“checkpoint”来实现这一点,但它应作为补充,而不是用来替代源代码管理。
- 一个集成开发环境,用于轻松加载和浏览你的模型(例如 Tabular Editor 2 或 3),以及一个文本编辑器,用于修改这些文件(例如 VS Code)。
注意
由于你修改的是本地元数据文件,这种方式不需要 Microsoft Fabric、Premium-Per-User,甚至不需要 Power BI Pro。
这种方式与其他方式的区别
这种方式与另外三种有些不同,因为智能体是在直接读取和修改元数据。 当智能体使用 MCP 服务器或 CLI 时,它是通过代码间接完成这些操作的。 因此也会带来一些关键的优势和挑战。
这种方式的优势
这种方式有一些独特的优势:
- 搜索:这种方式最大的优势,是让 AI 以最快、最高效的方式搜索或汇总语义模型。 无论编码智能体使用的是 Read 工具、Bash 工具,还是更复杂的语义搜索,它都能更快地在本地文件中查找特定词或模式,同时将 token 消耗降到最低。
- 更容易“撤销”更改:当你更改模型元数据文件时,更容易回退到之前的 checkpoint 或 commit。 如果你是在 Power BI Desktop 中对已打开的本地模型,或在服务中对已发布的模型进行更改,这就难得多。 这其实是个巨大的优势,因为一旦你把模型“弄坏”了或执行了破坏性操作,如果你直接在本地或远程语义模型上操作,而不是在它的元数据上操作,就可能会很麻烦。
- 简单:因为你基本上只是在修改文本文件,所以很容易看懂智能体在做什么,以及它改了哪些内容。 你也不需要安装任何东西;想提升智能体表现,本质上就是改进你的上下文文件和提示词。
- 安全:因为你不依赖智能体执行任意代码或使用 MCP 服务器工具,这种方式风险更低。 由于你可以把智能体限制在容器里,甚至使用本地 LLM,而不用依赖模型的代码生成或工具调用表现,所以可能更容易把它做得更安全或更私密。
- 模块化:你可以把这种方式和其他方式组合使用。 例如,智能体可以借助 MCP 服务器和代码来操控模型元数据,而不是直接写入其中。 在某些情况下,直接修改文件(例如只改一处)更快或更省事;但在另一些情况下则未必如此,因此智能体可以改用 MCP 服务器或代码。
尽管看起来简单,这种方法通常也伴随着最多的注意事项和限制。
这种方法的挑战
在智能体开发中,这里有几个挑战:
- 难以验证更改:在本地修改文件最大的隐患在于,你无法查询这些文件,也无法测试更改会如何影响数据或计算。 为此,你必须先在 Power BI Desktop 中打开模型,或将其部署到 Workspace,然后对其进行处理。 你可以把这个流程简化,甚至自动化(例如在工作区模式下使用 Tabular Editor 3,或使用 Fabric CLI)。 此外,如果更改导致 TMDL 无效,仅靠这些文件也很难验证(即使使用 TMDL 扩展也是如此)。 其他方法会限制可执行的操作,从而避免出现这种情况。
- 脆弱性:由于智能体只是直接修改文本文件,它很容易犯错,从而导致 TMDL 无效。 例如,TMDL 对空白字符敏感;缩进以及看似无害的语法改动,都可能导致文件无效。
- 复杂性:TMDL 很特殊,因为它包含三种及以上不同的语法。 一个 TMDL 文件既可能包含语义模型元数据,也可能包含 DAX 表达式、Power Query(M)表达式,少数情况下还会包含其他语法(例如用于原生查询的 SQL,或在 Power Query 集成下使用的 Python 和 R)。 这些嵌入式语法很容易让智能体混淆,导致在很长的 DAX 表达式里出现 TMDL 语法,或反过来。
- 新的元数据格式:TMDL 和 PBIR 都是新格式,在 LLM 训练数据中的覆盖相对稀少。 你甚至会发现,模型在生成或管理 TMSL 和旧版 Report 的元数据方面,可能比处理 TMDL 和 PBIR 更擅长。 因此,你需要投入更多精力去创建并维护上下文,才能正确地使用这些格式。
- 低效或缓慢:采用这种方式时,你要等智能体先找到要改的对象或属性,然后再生成用于替换的正确值。 另外,你还需要在能够从元数据“构建”模型的程序中进行验证。 对于许多简单改动以及大多数新增内容,这往往比你自己动手改要耗时得多(成本也高得多)。 当模式一致但值不一致时,这种方式才更有用(例如描述、显示文件夹或表达式)。 对于更大、更复杂的语义模型尤其如此。
- 不擅长生成新文件和属性:生成完整的新 .tmdl 文件是一个很漫长的过程,而且 LLM 很可能在过程中出错。
- 上下文衰减:如果智能体每次更改前都必须先读取模型元数据,会消耗大量 token,占满上下文窗口。 这会导致性能下降、成本上升,或更快触及会话限制。 当表包含大量度量值和列时尤其明显,因为这些内容都定义在特定表的 .tmdl 文件中。
尽管有这些挑战,某些情况下这仍可能是你的首选方法。
何时可能会使用这种方法
在少数情况下,相比其他方法你可能更想用它:
- 搜索或探索一个模型,尤其是你不是作者的模型。这应与在 Tabular Editor 或 Power BI Desktop 等其他工具中的探索同步进行;在那里你能更清楚地看到各个对象以及它们之间的关系,例如在模型关系图中。 例如,搜索某种特定的代码模式、列或属性,尤其是在你不知道确切名称或取值、但能大致描述它时。
- 一些用界面或脚本不太好做的简单/单项调整。例如重构已有的简单属性值(如显示文件夹名称),或从多个实例中移除 DAX 或 Power Query 表达式的一部分(例如某个筛选器)。
- 批量调整已设置好的对象名称或属性值。例如批量重命名或重构对象。 注意:当你需要修改多行属性时,即使是简单改动也可能变得棘手,因为 TMDL 对空白字符和制表符很敏感。
何时可能不该使用这种方法
也有一些情况下,这种方法并不理想;你应改用 MCP 服务器、编程接口或传统开发方式:
- 带依赖关系的更改。你对模型元数据做的很多更改,都会影响下游对象。 简单的例子包括重命名表、列或度量值;引用它们的表达式里可能并不会同步重命名。 如果你修改了需要更高模型兼容级别的属性,或修改了会与文档较少的属性和注释相互作用的属性,也可能遇到问题。
- 添加新属性和对象。 当你需要向模型添加新表、度量值和列时,智能体更容易在 TMDL 语法或缩进上出错。
- 需要验证的更改。 更改 DAX 和 Power Query 表达式可能会在模型元数据方面引发问题,因为你无法获得任何关于语法是否正确的反馈。
以上只是几个例子。 总结来说,处理元数据文件通常更适合用于读取与总结操作,或对现有对象和属性做一些简单更改——速度更快、效率更高。 而在大多数其他场景下,你应该改用替代方案。
在 TMDL 文件上使用智能体的成功建议
尽管这种方法很简单,但仍有很多事项需要牢记。 如果你不投入足够好的上下文,或使用速度较慢的模型,很容易得到糟糕结果或白白浪费大量时间。
- 使用检查点与源代码管理:在进行智能体开发时,能够快速、轻松地回滚更改至关重要。 这是这种方法的关键优势;别把它浪费掉,否则可能会破坏或丢失重要工作成果。
- 使用更快、每秒 token 数(tps)更高的模型:像 Cursor 的 Composer 或 Anthropic 的 Haiku 4.5 这类模型,最适合这种方式。 这些模型吞吐量很高,同时仍具备不错的准确性和遵循指令的能力。 这有助于抵消等待模型进行文件更改带来的低效。
- 上下文就是一切:除非你投入精力编写高质量的说明和提示词,否则很难用这种方式稳定成功。 这是一项前期投入,可能需要时间,但往往值得。
- 使用 Microsoft Docs MCP 服务器或 WebSearch / Fetch 工具:你可以让 agent 去检索有关元数据格式的信息,甚至获取关于语义模型的一般信息。 无论你采用哪种方式,这都是个实用建议;但如果 agent 会直接处理元数据,它尤其有帮助。
- 在 VS Code 中使用 TMDL 扩展:TMDL 扩展提供语法高亮和一定的验证,让你更容易处理 TMDL。 一些与 IDE 集成的编码 agent 也可以利用该扩展查看这些验证结果,从而改进输出。
- 每个会话都要验证:使用编码 agent 修改后,不要只阅读 TMDL 文件。 你应该在功能性工具中打开模型,实际查看改动,并识别任何错误或警告。 例如,如果你在 Tabular Editor 中打开模型,语义分析的警告和错误会提示你存在的问题;同时你也可以使用 Best Practice Analyzer 和其他工具来发现需要处理的事项。
- 考虑如何与 CI/CD 集成:这种方法最大的短板之一是,你在更改之后或更改过程中无法查询模型来进行验证。 一种应对方式是,在会话结束时建立流程,自动将模型部署(并重新处理)到沙盒 Workspace。 然后,你可以用 MCP 服务器或 Fabric CLI 等其他工具来查询模型。
- 不要只用这一种方法; 把它和其他方法结合:为了获得最佳效果,你最好把这种方法和 MCP 服务器或代码/API/CLI 工具结合使用。 这样,你既可以利用可编程方式更高效地完成批量操作,又能继续享受快速的模型搜索与摘要,以及对单个文件的修改。
- 在 Tabular Editor 中保持模型元数据处于打开状态:Tabular Editor 可以在每次更改后重新加载模型元数据,并帮助你验证更改。 使用 Tabular Editor 3 时,你可以获得语义分析和 DAX Code Assist,以及对最佳做法违规的自动扫描,并通过 DAX优化器找到瓶颈。 借助工作区模式,你还可以确保 Workspace 中的模型保持最新,以便查询。 如果你不想用 Tabular Editor,我们再强调一次:你最好用 Fabric CLI 设置某种形式的自动化部署到 Workspace。
- 使用驻留在终端中的 agent:和带用户界面的 agent 相比,像 Claude Code 或 GitHub Copilot CLI 这样的命令行 agent 可能会带来更好、更快的效果。 这只是作者的主观经验。
以上只是一些需要记住的事项。 我们会随着这一领域的发展持续更新本文;你可以将其添加为 Bookmark,并定期回来查看。
结语
对于 agentic 开发,其中一种方法是直接修改模型元数据文件。 这种方法最容易搭建和使用,但注意事项也最多,包括对良好上下文和提示词的高度依赖、验证结果的困难,以及 TMDL 中空白字符等特定挑战。 不过,这也是 agent 搜索和探索模型时最快、效率最高的方法;同时也是让异步(或后台)agent 在无人监督下审查或处理特定功能的最直接方式。
本系列的下一篇文章将介绍第二种方法:为 agent 提供一个模型上下文协议(MCP)服务器来操作模型元数据。


